How ShareChat built a scalable cost efficient ML Feature system
David Malinge,Ivan Burmistrov6 Mar, 2025

Introduction
At ShareChat, Machine Learning models form the backbone of our recommendation system, playing a pivotal role in delivering the most relevant and engaging content to our users. Our mission is to provide an exceptional user experience by ensuring that each user discovers content that resonates with their interests and preferences.
However, the success of these ML models heavily depends on the quality of data they are trained and evaluated on. This is where feature engineering becomes crucial - it's the process of transforming raw data into meaningful units of information, called features, that our ML models can effectively utilize.
A robust and scalable feature engineering system is essential for several reasons: it ensures consistency between training and serving, enables experimentation with various types of features, and maintains high performance at scale providing the ability to evaluate as many candidates as possible. In this blog post, we'll dive into how ShareChat built a scalable and cost-efficient ML feature system that powers our recommendation engine.
What are “Features” anyway?
A feature is pretty much anything that can be extracted from the data:
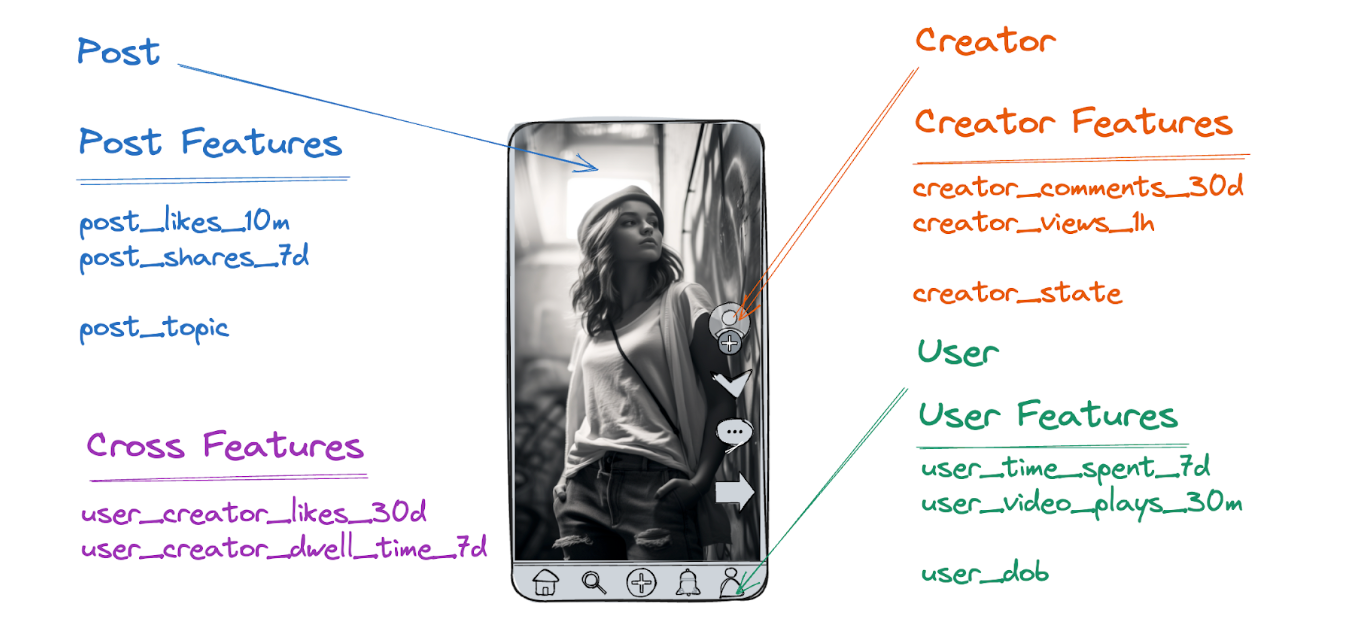
We compute features for different “entities”. A post is one type entity, a user is another one and so on. From the computation perspective, they are quite similar. However, the important difference is in the number of features we need to fetch for each type of entity. When a user requests a feed, we fetch user features for that single user. However, to rank all the posts, we need to fetch features for each candidate (post) being ranked, so the total load on the system generated by post features is much larger than the one generated by user features. This difference plays an important role in our story.
Challenges in Building Our Feature System
In developing our feature store system at ShareChat, we faced multiple significant challenges:
1. Real-time Processing Requirements
We strongly believe that real-time signals provide the most valuable insights for content recommendations. This means that our feature store needs to process and make features available almost immediately as new data streams in. Real-time processing is crucial for capturing user behavior patterns and content performance metrics as they happen, enabling our recommendation system to adapt quickly to changing user preferences and trending content. The real-time processing is especially important for dynamic features like user embeddings - the quality of the feed for the given user directly depends on how quick the updated user embeddings could reach the inference layer.
2. Complex Counter Features with Sliding Windows
One of our most demanding requirements was the need to maintain counter features across multiple sliding window ranges. For instance, tracking metrics like post views, likes, or shares across various time windows - from the last few minutes to 7 days and beyond. These features are essential for understanding both immediate content performance and longer-term engagement patterns.
The challenge here was two-fold: we needed to:
- Efficiently store and update these counters in real-time
- Ensure quick retrieval of these features across different time windows without significant computational overhead
3. High-Performance Serving Requirements
Our recommendation system needs to evaluate a large number of content candidates to select the best possible content for each user. This creates significant demands on our feature serving system:
- The system must handle high query loads during peak traffic periods
- Response times need to be consistently low (in 10s milliseconds) to maintain a smooth user experience
- The system must be able to efficiently autoscale to accommodate growing traffic while maintaining performance, without burning compute during low-traffic period
4. Cost Efficiency Requirements
While feature system is a crucial component of our recommendation system, it’s just one of the supporting components to our core which is advanced machine learning models. Both training and inference require significant computational resources, and if we can spend more resources we would get better results, leading to a better user experience. So, if other components like feature store can use fewer resources they should be optimized as much as possible to do so. This leads to the requirement for feature system to be as cost efficient as possible.
High-level design
The feature system consists of a few main components:
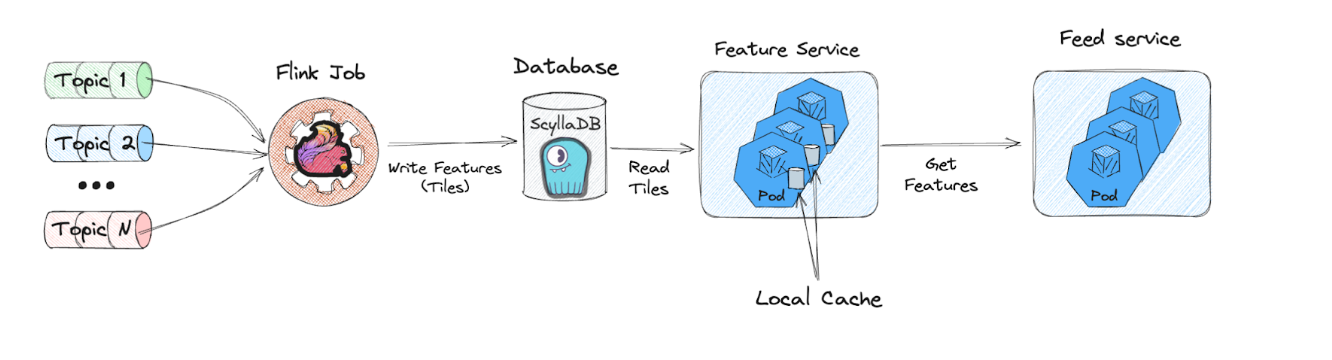
1. Real-time Data Streams
The input to our system consists of various real-time event streams capturing user interactions and content performance metrics. These include events like clicks, shares, comments, and other engagement signals that are crucial for our recommendation system.
2. Stream Processing Layer
Apache Flink jobs form the core of our stream processing layer. These jobs consume the input streams and pre-aggregate the data into time-based buckets we call "tiles". Each tile represents a specific time window (1 minute, 30 minutes, 1 day, etc.) and contains pre-computed aggregations for that period.
Using the tiles of different sizes allow reducing the amount of data required for serving requests like “the number of likes in the last 1 days for the given post”. For instance, assume we want to compute last 1d number of like at the moment of 15:37 for a given day. We would need to cover the day ending at 15:37 with tiles, like this:
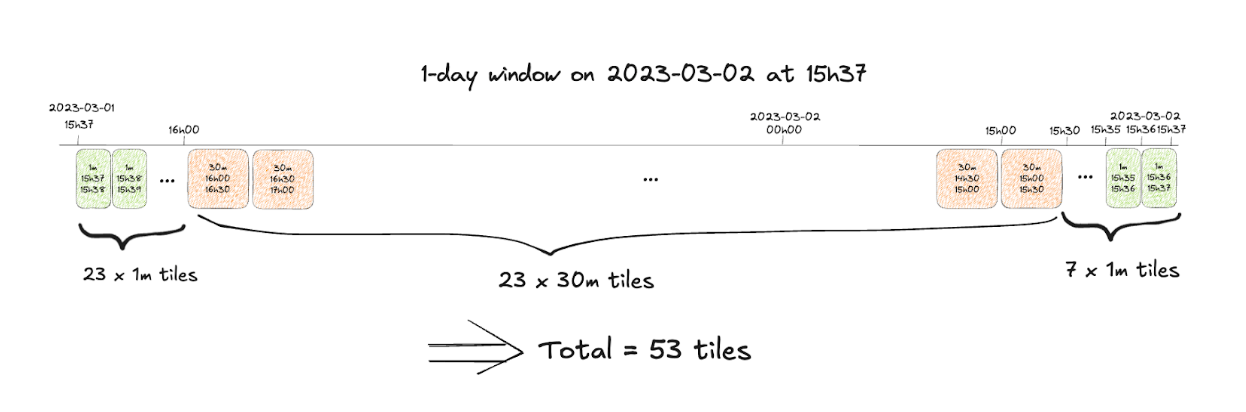
So we would need to request 53 tiles to process this request.
3. Storage Layer
We use ScyllaDB as our storage backend, which provides high throughput and low latency access to our pre-aggregated tiles. ScyllaDB's architecture is particularly well-suited for our use case as it can handle high write loads from our Flink jobs while simultaneously serving read requests from our Feature Service.
4. Feature Service
The Feature Service is our serving layer that handles real-time feature requests from the recommendation system. When a feature request arrives, this service:
- Checks the local cache if the same request has been already processed recently. Returns the result immediately if it did, if not:
- Determines which tiles are required to compute the requested feature
- Retrieves the relevant tiles from ScyllaDB
- Performs final aggregations across tiles to compute the exact feature values
- Returns the computed features to the calling service and caches the computed result
Tiles optimizations
The initial database schema and tiling configuration led to scalability problems. Original schema mapped each entity into its own partition, with timestamp and feature name being ordered clustering columns.
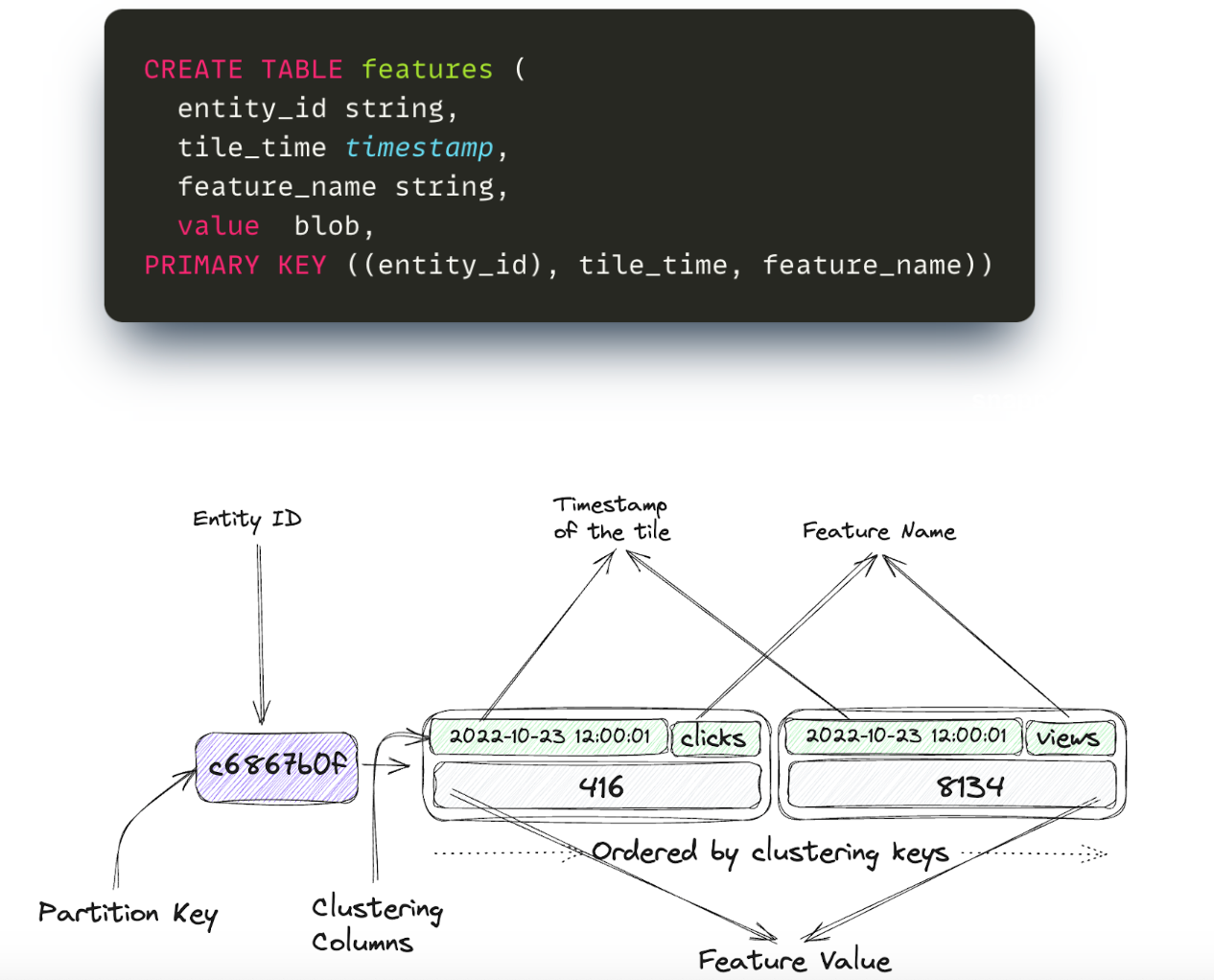
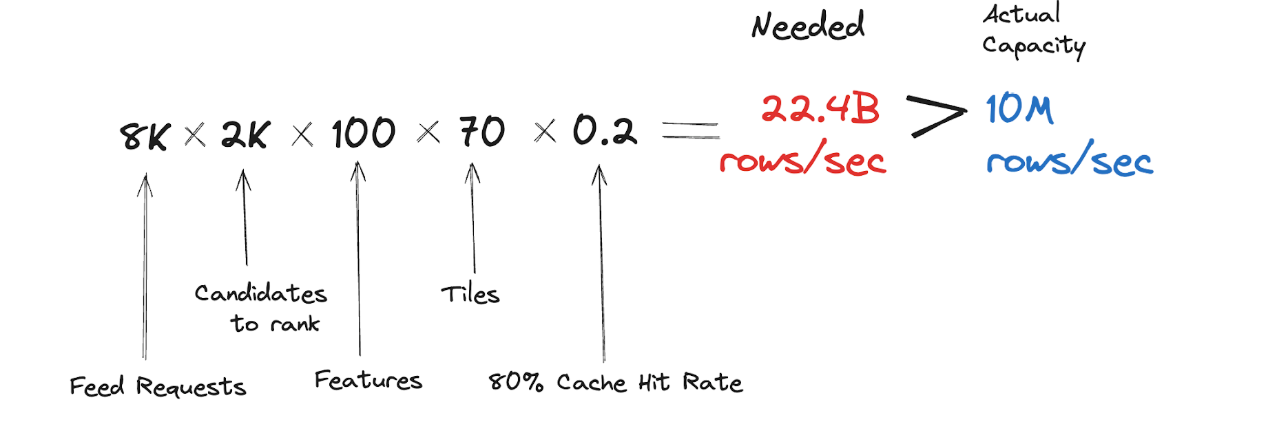
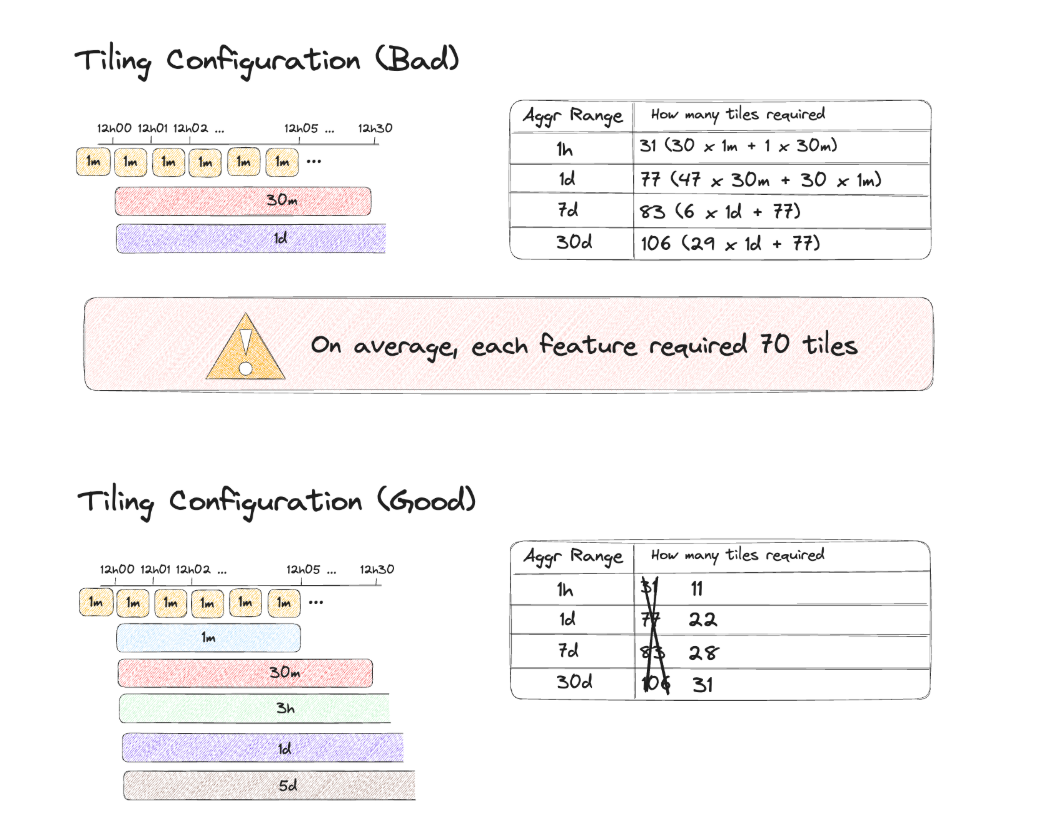
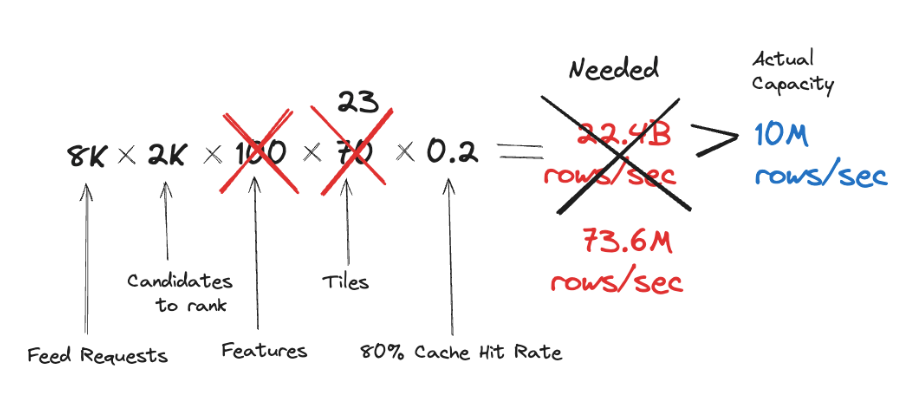
Tiles were computed for segments of one minute, 30 minutes and one day. The most popular requested aggregation ranges were 1 hour, 1 day, 7 days or 30 days, and the number of tiles required to be fetched were 70 per feature on average.
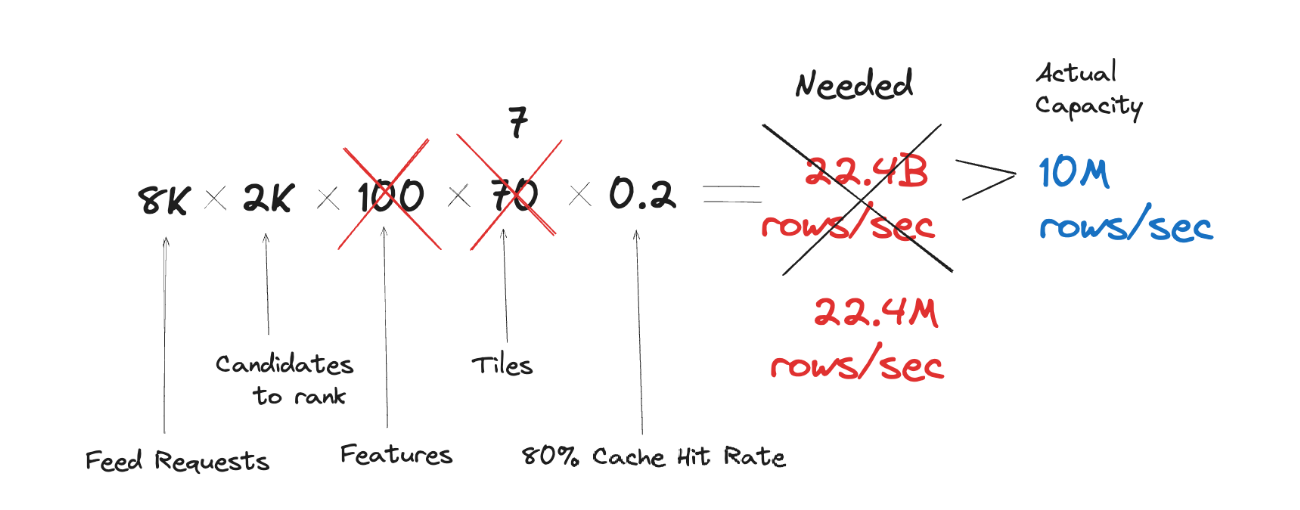
If we do the math, it becomes obvious why this approach didn’t scale well. At the moment of testing, the system has around 8K rps for fetching the feed, with around 2K candidates being ranked:
Step 1: Make db schema more “compact”
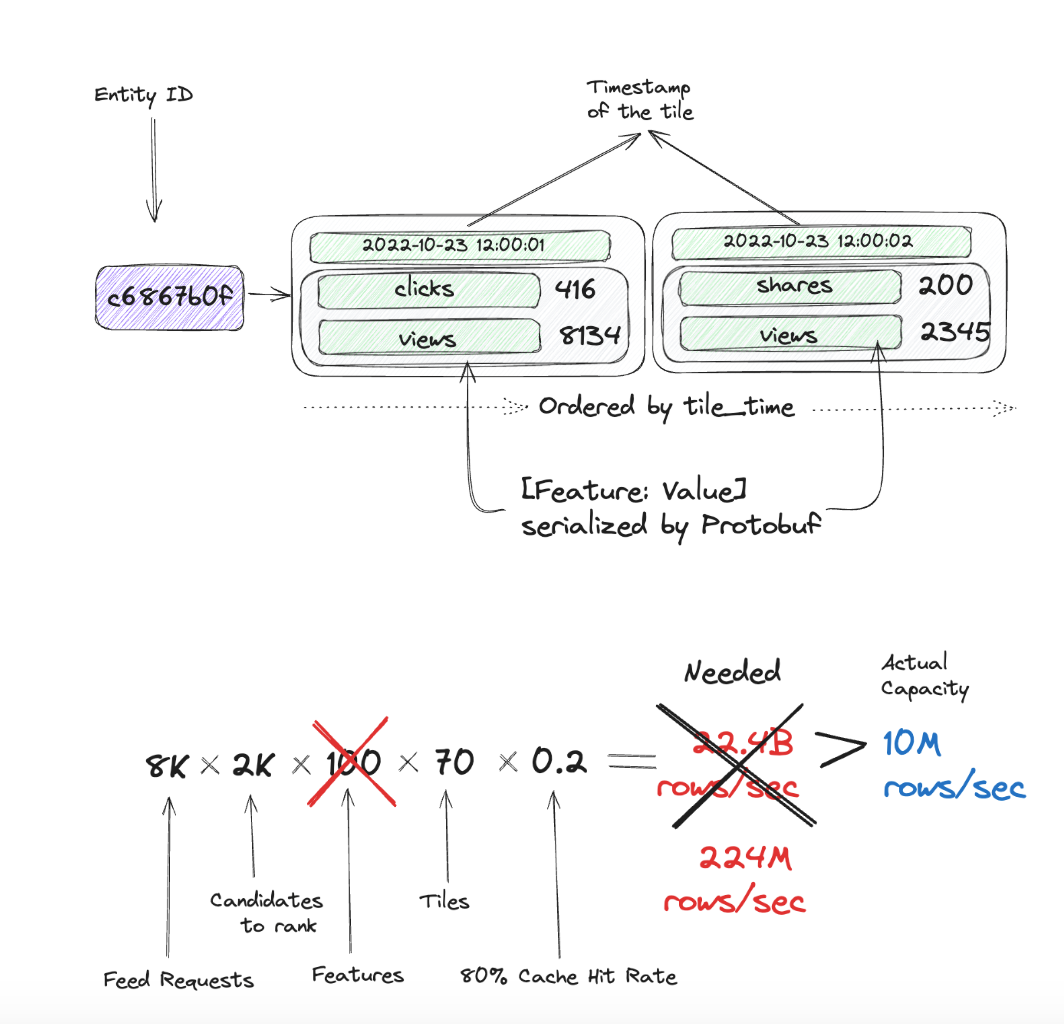
While ScyllaDB is an extremely efficient database and does its best to retrieve rows from the same partition efficiently, processing each row still yields some overhead. In fact, in our case the number of requested rows per second from Scylla served as a great proxy for the efficiency of the whole system. So, reducing this number means improving the scalability.
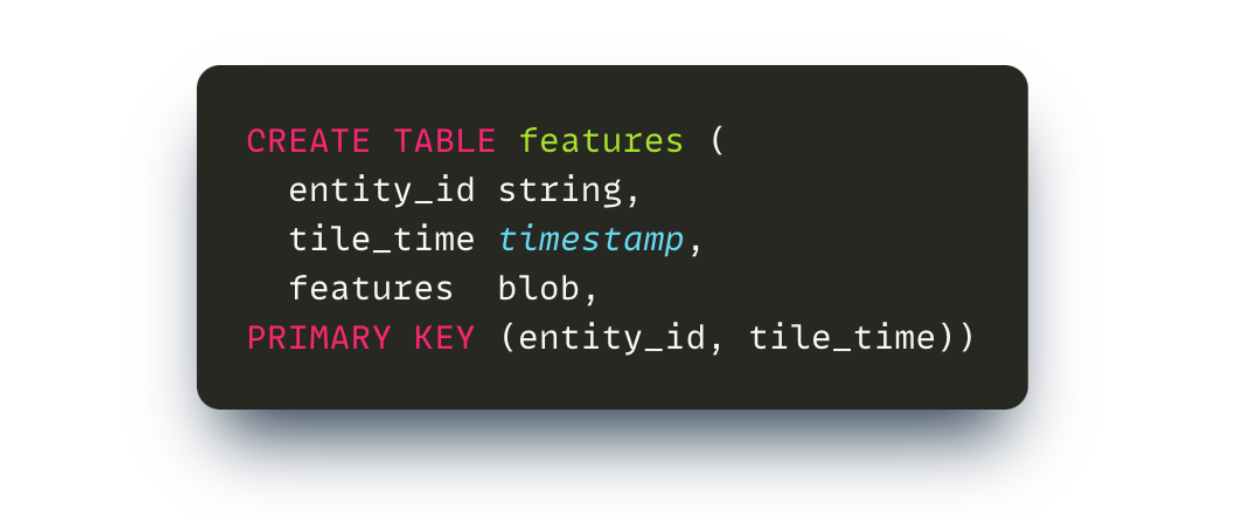
In the initial schema, feature names were clustering columns - that is, each feature had its own row. However, a lot of features are typically being requested together. For instance, we can request all counters features for the given post at once. This observation leads to a question: if features get requested together, maybe they should be stored together as well? The updated schema utilized “fat rows”, as is - multiple features for the same tile stored together in a serialized form:
Step 2: Tune tiling configuration
The initial tiling configuration consisted of only 4 tiles - 1 minute, 30 minutes and 1 day. Picking the right tiling configuration is a trade-off between efficiency of stream processing layer (Apache Flink job) and feature serving layer (Feature Service). Computing more tiles means fewer need to be fetched for a given range, however this increases the compute on the stream processing layer. We found that in our case adding 3 more tiles didn’t degrade stream processing significantly, while giving a huge boost to the serving layer. We added 5 minutes, 3 hours and 5 days tiles. This resulted in 2 to 3 times less Scylla rows required to be fetched:
Step 3: Smarter tiles fetching & combining
Initially, the approach for covering the requested range with tiles was quite simple recursive algorithm which is easier to explain using a picture. Let’s get back to an example where we want to compute 1d aggregation range at the moment of 15h37m:
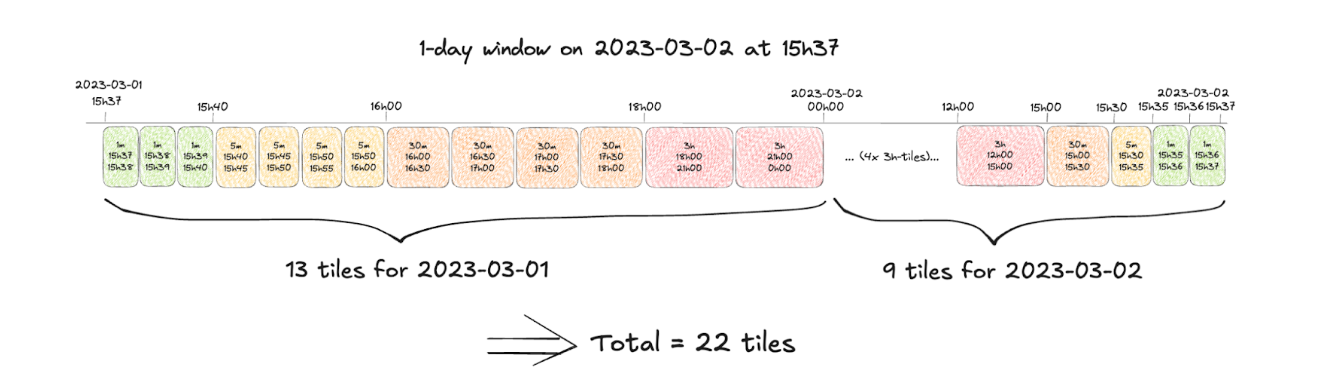
22 tiles is already quite an improvement from 53 tiles due to the changed tiling strategy.
But what if 15h37m is the current time? Which is actually always the case, as the features requested are of “views in last 1d”, “likes in last 7d” kind. This means we can use the “current” 1d tile, and the composition would look like this:
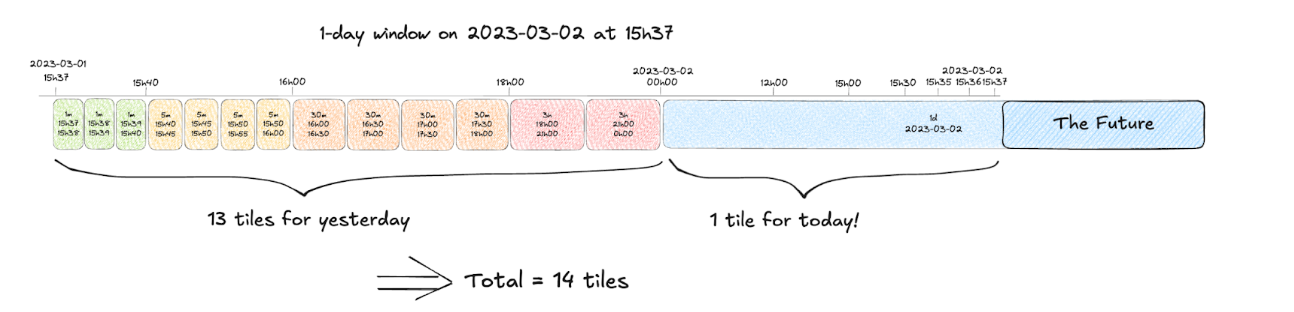
Down to 14 tiles instead of original 22, not bad!
But what if we allow ourselves to use not only operation of addition, but subtraction as well? In this case, we can optimize the left side of the picture too:
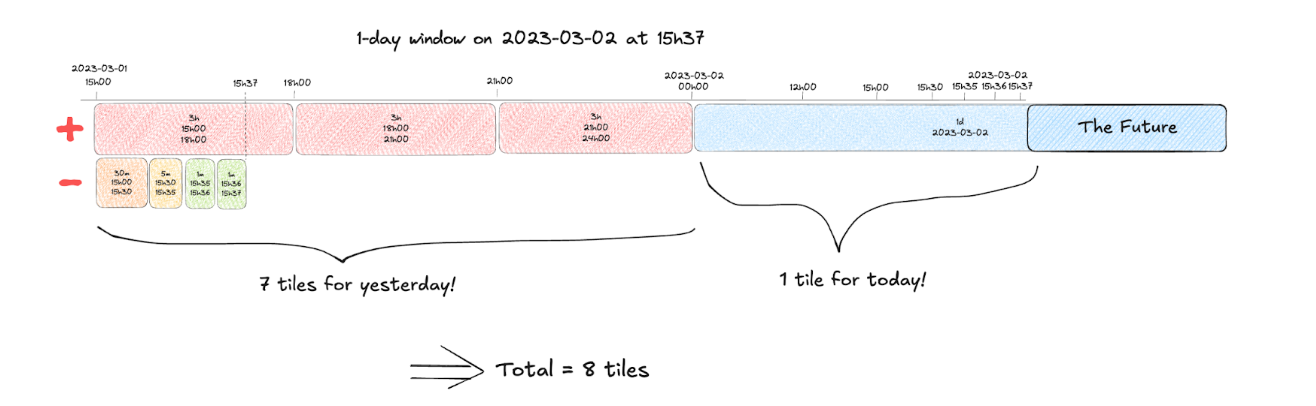
Overall, down to 8 tiles from original 22!
Incorporating a smarter algorithm into fetching the tiles allowed us to further reduce the load on database 3-4 times - to the average of 7 tiles.
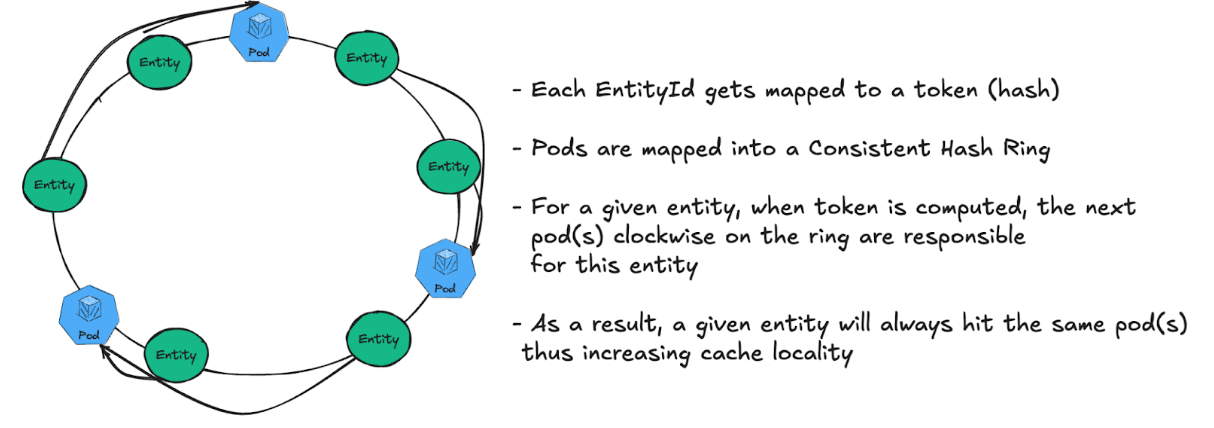
Cache optimizations
In all the calculations above, we used 80% as the percentage of cache hit rate. This figure was our initial cache hit rate - due to the local nature of our cache and multiple number of replicas, cache hit rate wasn’t particularly high. An obvious improvement to this situation is using consistent hashing approach: for the given entityId, instead of hitting an arbitrary replica of feature service, we can hit the one(s) responsible for the given entityId :
With Consistent Hashing approach, we managed to bring Cache Hit Rate to be as high as 99%:
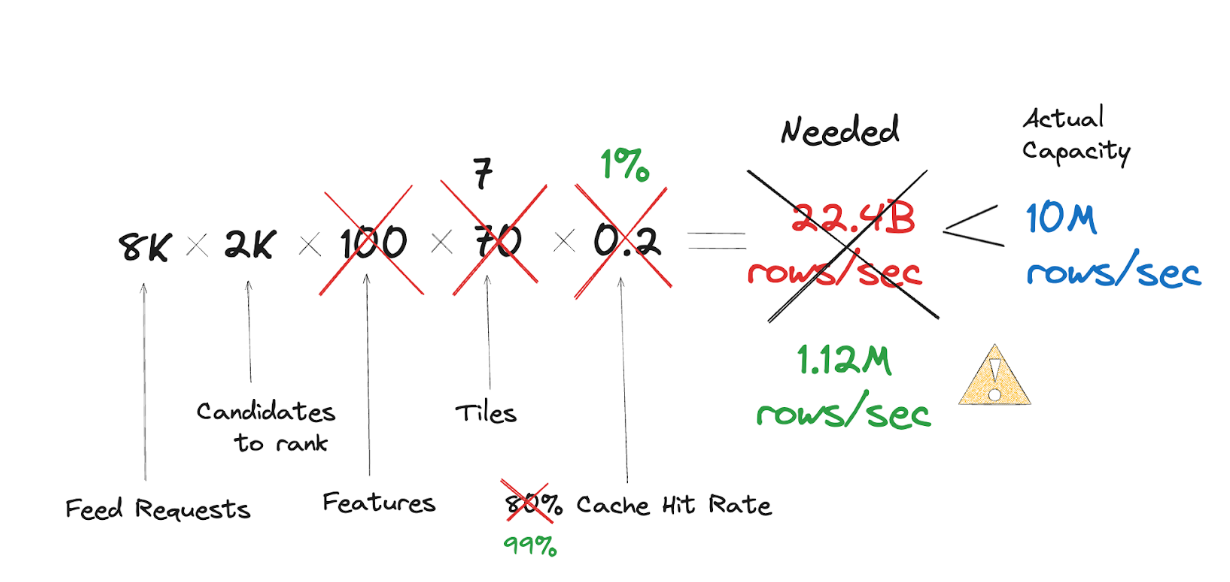
And in the end, our initial Scylla cluster turned out to be over-provisioned so we even managed to scale it down.
Conclusion
Building a scalable and cost-efficient feature system for ShareChat's ML-driven recommendations presented significant challenges. In this post, we wanted to touch on some of the ones we have faced with our counter features.
The main takeaway? Don't underestimate the power of back-of-the-envelope calculations, especially when applied to data modeling.
Another key lesson: always challenge the status quo. For instance, our smarter tiling strategy, which halved the number of fetches, came months after the counters were already in production and led to tremendous savings on compute.
This iterative approach, combined with a focus on first principles, has allowed us to build a robust and performant system that continuously improved while slashing costs. In the past year, we have cut the cost of our feature systems by 10x through multiple optimizations like the one discussed in this article as well as optimizations on the stream processing, e.g. making it autoscalable.
We're excited to continue pushing the boundaries of feature engineering at ShareChat. Now, onto the next challenge!

