Scaling Recommender System Training on Low-Cost GPUs at ShareChat
Alykhan Tejani , Jatin Mandav27 Jan, 2025

Part 2 is here! Dive into the Weekly Tech Blog Series focused on Innovation and Cost Efficiency. If you missed it, be sure to catch the first part of the series here. Stay tuned for more insights every week!
At ShareChat, delivering personalized recommendations to millions of users requires building and training large-scale recommendation models. In order to effectively recommend content to millions of users, ShareChat and MOJ leverage multi-task learning techniques that predict multiple user actions, such as likes, shares, downloads, and video watches. This approach allows the models to better understand user preferences across different engagement signals. ShareChat employs MMoE (Multi-gate Mixture of Experts) architectures, while MOJ utilizes PLE (Progressive Layered Extraction) models. Both architectures enable learning multiple tasks within the same model, facilitating cross-learning between different user actions. This design not only improves recommendation accuracy but also allows for a more efficient system by eliminating the need for separate models for each action, leading to significant computational savings and a more streamlined infrastructure.
Scale of ShareChat and Moj Rankers
Both our apps, ShareChat and Moj, operate at a very large scale with ranking models trained on vast amounts of data to deliver personalized content effectively to millions of users. ShareChat’s Video ranking handle handles embeddings for around 55 million post IDs and more than 80 million user IDs, with approximately 60GB of model size encompassing roughly 6.63 billion parameters. Meanwhile, ShareChat's Image ranking model supports 28 million post IDs and 50 million user IDs, with size around 25 GB and 3.98 billion parameters. MOJ video ranker is of a similar scale with embeddings for 44 million post IDs and 31 million user IDs, amounting to 55 GB of model size and 3.70 billion parameters. Even though our monthly active user base and content corpus is much larger than these embedding sizes, we need to limit our embedding tables to smaller numbers in order to keep resource usage and costs in check while still achieving high model performance. These large-scale ranking models highlight the platforms’ commitment to serving diverse, personalized content at a massive scale, requiring advanced infrastructure and optimization techniques to maintain efficiency while training on billions of examples.
However, training these models effectively across distributed hardware while maintaining both performance and cost-efficiency is a significant challenge. Distributed training is essential because the sheer scale of data and model sizes involved exceeds the capacity of a single machine, necessitating the use of multiple devices to process data and compute gradients in parallel. While TPUs (Tensor Processing Units) are highly specialized for machine learning workloads, offering unparalleled performance for synchronous training and large-scale matrix computations, they come at a premium price and are only available in select regions. In contrast, GPUs (Graphics Processing Units) are more versatile and widely available, with significantly lower costs but traditionally less efficient for tasks like synchronized training across distributed setups. To overcome these limitations, we’ve developed an innovative approach that leverages the affordability and accessibility of GPUs, while incorporating techniques that allow us to achieve TPU-level accuracy at a fraction of the cost.
Dynamic Embedding Tables with TensorFlow Recommenders
Our recommendation models rely on dynamic embedding tables to effectively handle the growing diversity of user and content interactions. For this, we use TensorFlow Recommenders dynamic embeddings library, which implements cuckoo hashing to ensure that each ID we want to embed—whether for users, posts, or other entities—has its own unique embedding. Unlike traditional hashing, which can lead to collisions where multiple IDs share the same embedding, cuckoo hashing guarantees no collisions, thereby improving prediction accuracy by ensuring that each entity is represented individually.
The dynamic nature of these embeddings allows us to adapt to new users, posts, and interactions in real-time, providing a more personalized model for each individual entity. Additionally, TensorFlow Recommenders’ built-in eviction policies help manage memory usage by removing stale or less-used embeddings, preventing unbounded growth and ensuring optimal resource allocation in production environments.
Hybrid Training Approach: Combining Synchronous and Asynchronous Techniques
To effectively train large models across multiple GPUs, we employ a hybrid approach, where different components of the model leverage distinct training strategies:
- Synchronous Training for Dense Model Components
We use Horovod to synchronously train the dense parts of our models across multiple nodes equipped with lower-cost GPUs. This ensures that our dense layers—crucial for learning global patterns—are updated consistently across all devices. Synchronous training helps us achieve the same high level of accuracy as TPU-based systems, while maintaining the advantages of a more cost-effective infrastructure. Horovod’s distributed framework enables scaling across GPUs without sacrificing model consistency or accuracy.
- Asynchronous Training for Dynamic Embeddings with a Parameter-Server Style Approach
For the dynamic embedding tables, we use a parameter-server-style strategy where the embeddings are partitioned across multiple devices. Since each partition is responsible for a subset of the embeddings, updates only need to happen on the specific device where the embedding resides, eliminating the need for synchronization across devices.
This asynchronous update process allows us to scale efficiently, enabling extremely large embedding tables—such as learning unique embeddings for every user. This approach is particularly effective given the scale of ShareChat’s ecosystem, where embedding tables for all users may require up to 40GB of memory.
Maximizing Throughput with TensorFlow Distributed Dataset Service
Efficient data loading and transformation are critical for ensuring that GPUs remain fully utilized during training. To eliminate potential I/O bottlenecks, we utilize TensorFlow’s Distributed Dataset Service (DDS) to parallelize data loading and preprocessing. DDS allows for:
• Dynamic Data Pipelines: Supporting arbitrary tf.data transformations in real time.
• Worker Pool Distribution: Mitigating I/O bottlenecks by offloading preprocessing to worker pools, ensuring GPUs remain fully utilized.
This setup minimizes data preparation delays and enables rapid experimentation, critical for dynamic environments where platform behaviors evolve daily.
To better understand how DDS orchestrates efficient data handling, consider the diagram below, which illustrates the flow of data preprocessing requests from clients to a distributed pool of workers via a central dispatcher:
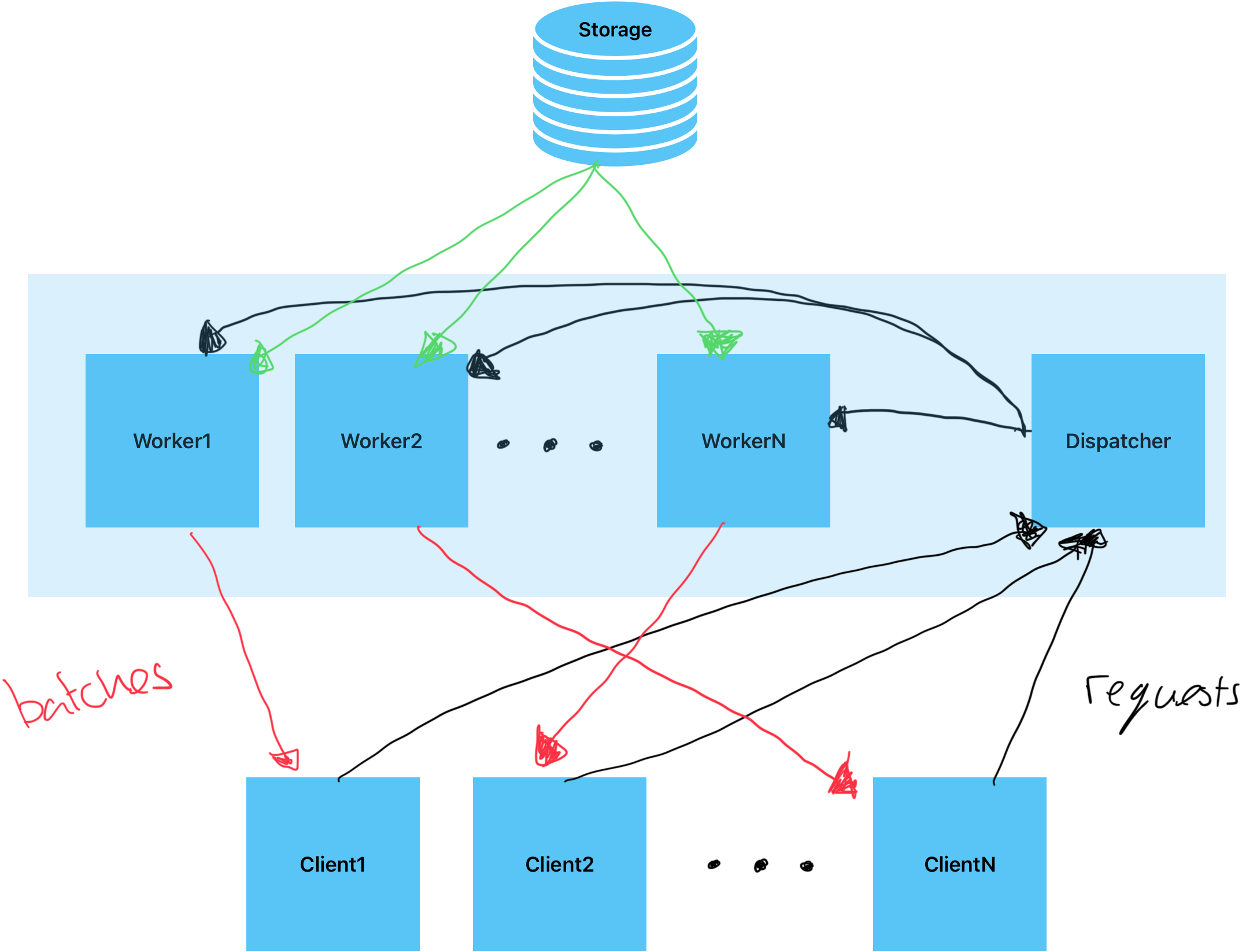
Here, clients request preprocessing tasks, which the dispatcher assigns to available workers. These workers, connected to shared storage, generate batches in parallel, feeding training pipelines without introducing I/O bottlenecks. The workers in this case are CPU machines which just preprocess data, leaving the clients to do the model training on GPU. This distributed approach ensures efficient scaling and sustained GPU utilization.
Results: Achieving TPU-Level Performance at a Fraction of the Cost
Our hybrid approach—combining synchronous training for dense model components, asynchronous updates for embeddings, and parallelized data pipelines—has enabled us to achieve TPU-level performance and accuracy on a far more cost-effective GPU-based infrastructure.
By transitioning to GPUs, we can also co-locate compute resources with our data, eliminating data transfer costs entirely. For example, a case study with ShareChat’s video ranker demonstrated a remarkable 75% cost reduction, showcasing the effectiveness and efficiency of this approach in production environments.
In addition to cost savings, our solution delivers impressive data throughput during training. While our previous TPU-based setup achieved approximately 215k samples per second, the hybrid GPU-based approach closely matches this performance, reaching 200k samples per second. This consistency in throughput, combined with significant cost reductions, underscores the scalability and practicality of our hybrid training solution.
We are hiring! Check out open roles at https://www.linkedin.com/company/sharechat/jobs

