3MASSIV: Multilingual, Multimodal and Multi-Aspect Dataset of Social Media Short Videos
Mayank Maheshwari, Vaibhav Mishra, Akash Sarkar, Vikram Gupta6 Jul, 2022

As more and more people converge on various social media platforms, it’s hard to ignore the impact it has on our lives and the wider society in general. The rise of the social media space has also effectively changed the way we consume content - for information and for entertainment.
The popularity of short video platforms - like Moj, and others - has also accelerated the growth of short videos with millions of videos uploaded on Moj every single day.
A shift that’s become all too prominent is the rise of short videos. As the growth has been exponential, it’s crucial to develop a better semantic understanding of this novel format. There is no dearth in literature for a better semantic understanding of long-form and micro-form videos but given the unique nature of short videos, it cannot be directly translated to model the understanding of short videos.
To bridge this gap, we introduce our work, 3MASSIV: Multilingual, Multimodal and Multi-Aspect Dataset of Social Media Short Videos, which was presented at the Conference of Computer Vision and Pattern Recognition (CVPR), 2022 held at New Orleans, Louisiana. This work was done in collaboration with our incredible collaborators from University of Maryland, College Park, USA.

There are several aspects that make short videos unique.
1) Unique Concepts: Short videos demonstrate novel and trendy concepts such as pranks, fails, philanthropy etc. which are not captured by previous datasets but are immensely popular on social media.

2) Unique Audio Types: The audio types vary as creators experiment with various audio renditions like lip-synced songs to dialogues, or instrumental music. 3MASSIV captures these variations to cover the broad-spectrum of social media content.

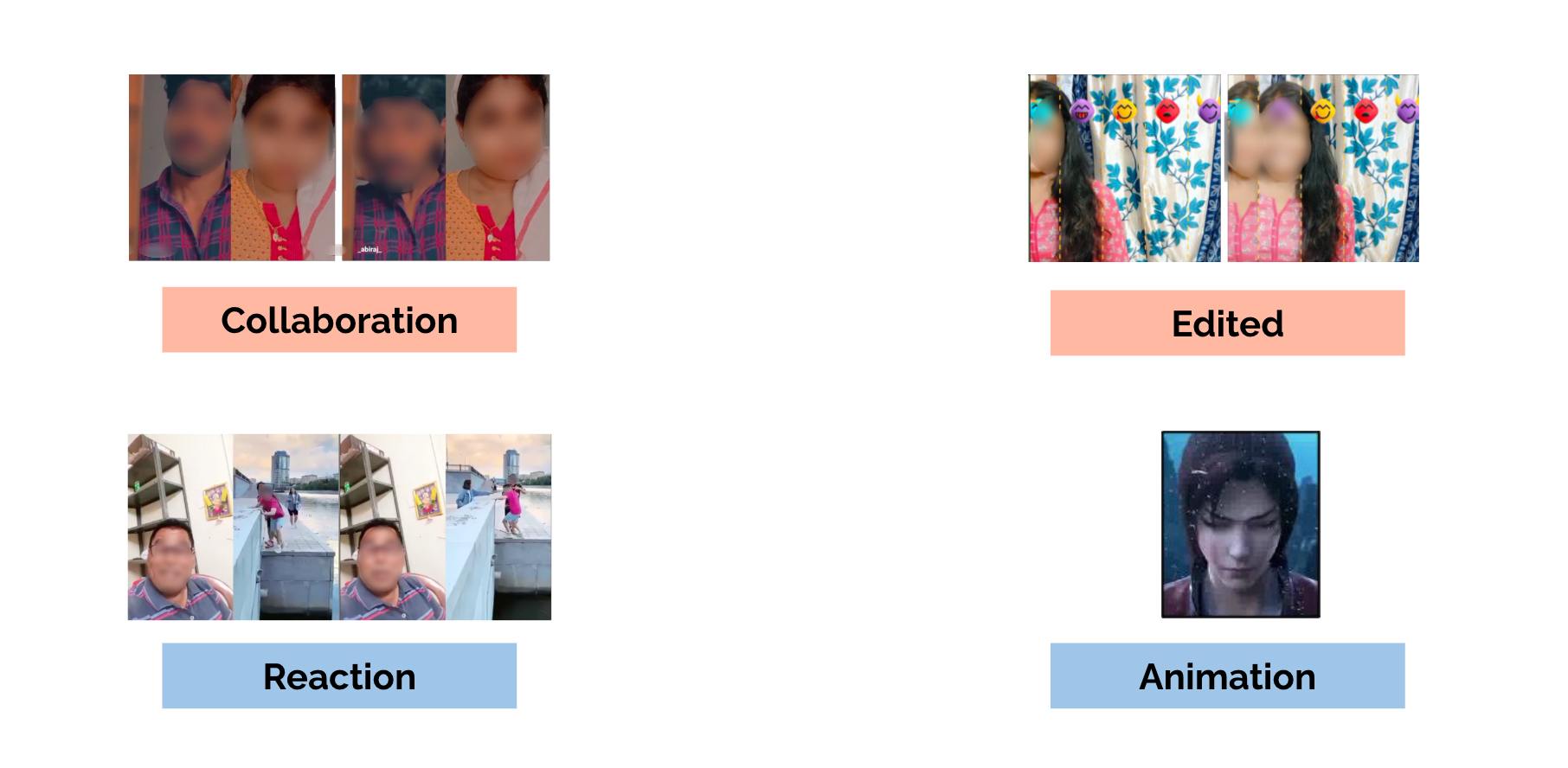
3) Unique Video Types: 3MASSIV also comprises eight different unique video types like collaboration, reaction, edited videos, animation and more, which are quite unique to these new age short videos.
4) Linguistic Diversity: Social media platforms are linguistically rich as users from different geographies engage and interact. 3MASSIV contains videos from 11 Indic languages which include Kannada, Tamil, Marathi, etc with Hindi emerging as the prominent language.

5) Fast Evolving Trends: Short videos are heavily influenced by global trends and news and thus demonstrate a lot of variety. We sampled videos across long durations so that 3MASSIV captures these nuances.
6) Shorter Narratives: The short videos on social media platforms are created with a short-narrative or script in mind. These byte-sized (~20 seconds) videos are complete in themselves which make 3MASSIV unique in comparison to other video forms.
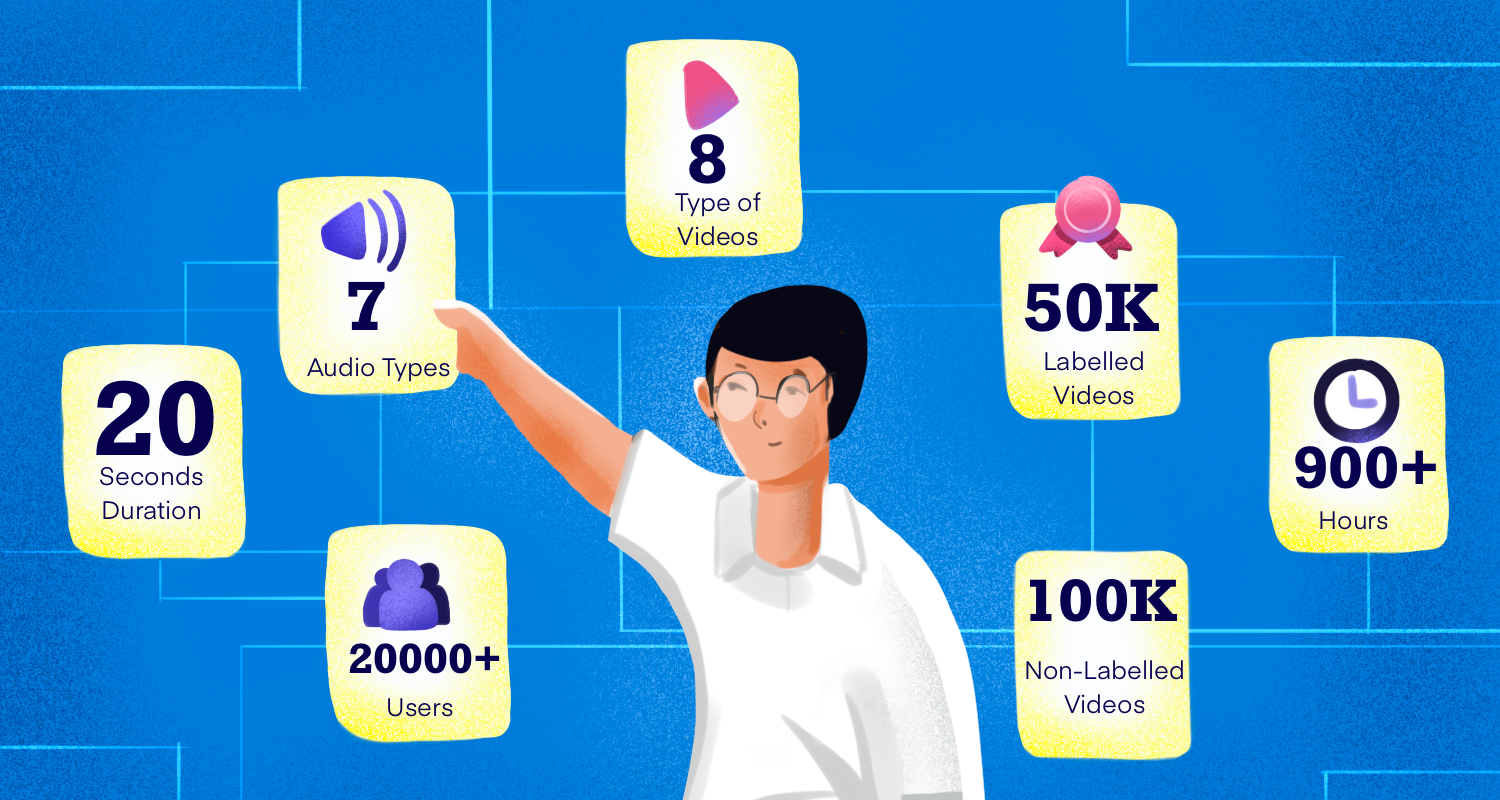
To recap, 3MASSIV contains annotations for 34 concepts and 11 affective states in 11 languages across eight videos and seven audio types. The total duration of these videos is approximately 900 hours spread across 50,000 labelled videos and 100,000 unlabelled videos sourced from 20,000 creators with an average duration of 20 seconds.
Due to these rich, novel and multi-aspect annotations, 3MASSIV can be used for studying multimodal content understanding systems, user-modelling, affective computing, mono-lingual and cross-lingual linguistic study and temporal analysis.
Conclusion
Even as the short video content continues its meteoric rise, the format hasn’t been investigated enough in the Computer Vision and Artificial Intelligence communities. With 3MASSIV, we are releasing a large-scale labelled dataset with the hope of bridging the gap in the current semantic understanding of short videos. We’ve also successfully established that 3MASSIV is dynamic and temporal in nature, enriched with various annotations, which can help us to do better user-modelling and cross-lingual tasks. We hope to build a better multimodal and multilingual semantic understanding of short videos for concepts, affective states, media types, and audio language.
License
3MASSIV dataset is available for research purposes only. Any commercial use of the dataset is strictly prohibited.
We are hiring!
At ShareChat, we believe in keeping our Bharat users entertained in their language of preference. We are revolutionising how India consumes content and the best in class AI & ML technology is at the forefront of this transformation. In addition, you'll also get the opportunity to work on some of the most complex problems at scale while creating an impact on the broader content creation ecosystem.
Exciting? You can check out various open roles here!
To read more about this dataset, click here.
Illustrations - Harita.

