ShareOCR: The end-to-end OCR for Indic content: Part 1
Rishabh Jain, Vikram Gupta, Hastagiri Vanchinathan, Debdoot Mukherjee27 Sept, 2021

Written by Rishabh Jain, Vikram Gupta, Hastagiri Vanchinathan, Debdoot Mukherjee
ShareChat is the leading social media platform in India & Moj is India’s preferred short video destination. Both of them allow users to share their opinions, record their lives, and make new friends — all within the comfort of their native languages. Our content consists of images and videos, most of which are created and uploaded by our users.
In our products, ShareChat & Moj, we depend heavily upon the various Indic text scripts present in images and videos. The text embedded in videos and images is an extremely important feature in tasks ranging from recommendation, content understanding, NSFW detection, offensive content detection, bait detection, etc. One such example can be seen in Fig 1.

The standard approaches of extracting text from images and videos come under the umbrella of Optical Character Recognition(OCR) methods.
The uniqueness of the content, multilingual nature of text and scale of our content pipelines makes it infeasible to use out-of-shelf OCR solutions.
Since our content is user generated, we also have a significant percentage of non-dictionary words attributed to misspellings, hashtags, slangs etc.
The diverse-Indic script nature of the problem is quite challenging, as most of our content includes multiple scripts present in the same image that needs to be detected, identified, recognized, and in the end, woven with each other to make meaningful sentences from those words. The image shown in Fig 5, is the standard example we commonly find in ShareChat & Moj. Keeping all these things in mind, we decided to build an end-to-end system in-house.
In this two-part series, we present our experiments with ShareOCR, an in-house OCR system developed by the ShareChat & Moj content-intelligence team that handles millions of posts a day. Though ShareOCR is an image-based-OCR system, it can also be extended for videos by using a decoder module that takes video input and returns important frames. We explain our video-decoder algorithm for ShareChat & Moj videos in Part 2 of this article.
About the data
The first exciting question that comes with an artificial intelligence problem is the data.
How do we get the data that is similar to our use-case?
Domain Gap !!
One option was to use standard datasets, e.g., COCO-text, SVT, etc., or human-annotated examples. However, we did not find similarities between COCO-text, etc. and the images that we have at ShareChat and Moj. Also, due to the scale and diversity in Indic scripts, human-labeled annotations were very expensive.
The major differences between the publicly available datasets and our data are:1. Language: Standard datasets are mostly single language-based, mostly English. While we have content in 15 Indic languages. Often multiple languages are present in the same example.2. Types of background: Standard datasets feature text instances often shot on roads and from signboards. Most of our content is overlaid on synthetic and digital backgrounds in decorated fonts.3. Content-Understanding: Standard datasets have the sole goal of correcting isolated text instances, while our datasets have meaningful text phrases, and the final output must reflect the creator-intent.
We compare our posts with respect to a standard dataset (SVT) in Fig 2 and Fig 3.


So, we moved to the other common alternative, which is to artificially generate image examples by putting text instances on a given set of backgrounds with the help of image segmentation techniques. But, we did not find any good enough existing image-processing methods which support overlaying different fonts of more than a dozen Indian scripts on synthetic backgrounds. Most of them suffered from encoding and sequential problems (what we read as humans, and what Unicode translates the sequence to, is different). A common idea was to generate the data using the most common apps that our users use for generating content. But, there is a huge-list of them and automating them to scale was out of scope for us. Also, capturing the user intent for a creator-base as big as us is a humongous task.
We had a couple of providers in the form of off-the-shelf models and third party APIs. We used them for generating samples of output data for us. But, as we faced unique challenges in handling diversity in Indic scripts and just-a-different way of text overlaying than normal OCR, they were not up to the mark metric-wise as we expected. Hence, cannot be directly used for training purposes.
We were well aware of their shortcomings and the cases they failed the most, and hence we used weak-supervision learning techniques to solve the problem for us. We also corrected the data using different approaches, more about which we will discuss in Part 2.
We decided to build an in-house model, as the existing solutions were not up to the mark, and quite expensive, for a company like us, which have x million of posts and videos created every month. Also, by building an in-house model, we can iteratively improve the performance both in terms of computation and correctness.
Some examples of imperfections are shown in Fig 4. We also used human-annotated examples on our data to verify the effectiveness of our approach.

We started solving the problem for Hindi language posts first, as it is the most common language of our user base. We hypothesized that it should scale well enough to other Indian languages, which we verified by human analysis of the result of our models. How we include other languages in the system will be covered in Part 2 of this article.
As shown in Fig 5, most Hindi posts contain words that are part of both Latin and Devanagari scripts, and the same applies to our other languages as well.

The end-to-end Pipeline
Let us now discuss the end-to-end OCR pipeline now. Given an image, our OCR pipeline consists of identifying different regions of text (text-detection) followed by decoding each region into individual word instances (text-recognition). The basic pipeline flow is shown in Fig 6.
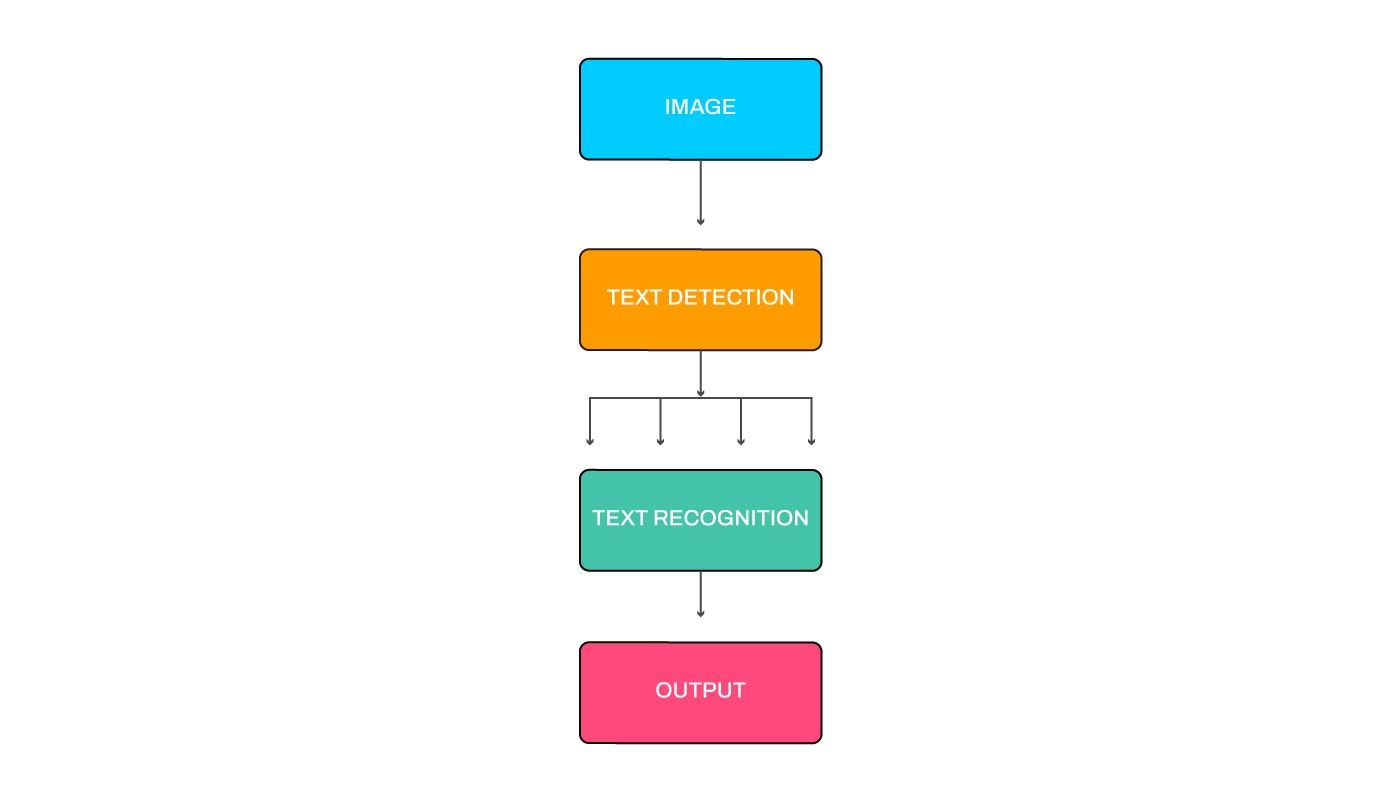
Text Detection
The first significant challenge is to detect areas of text inside an image. The common approach for this step includes drawing quadrilaterals around each word or line of text. The detected areas are then cropped out from the original image and fed as the input to the next steps.
While designing the OCR system, we had both computational complexity and correctness in mind, as the system needs to scale up to the heavy usage and use-cases. We tried models, like Single Shot Detection[4] and R2CNN[5], but keeping in mind the tradeoff between computation and correctness, we settled for the EAST [1] model. The modular architecture of the EAST network is shown in Fig 7.
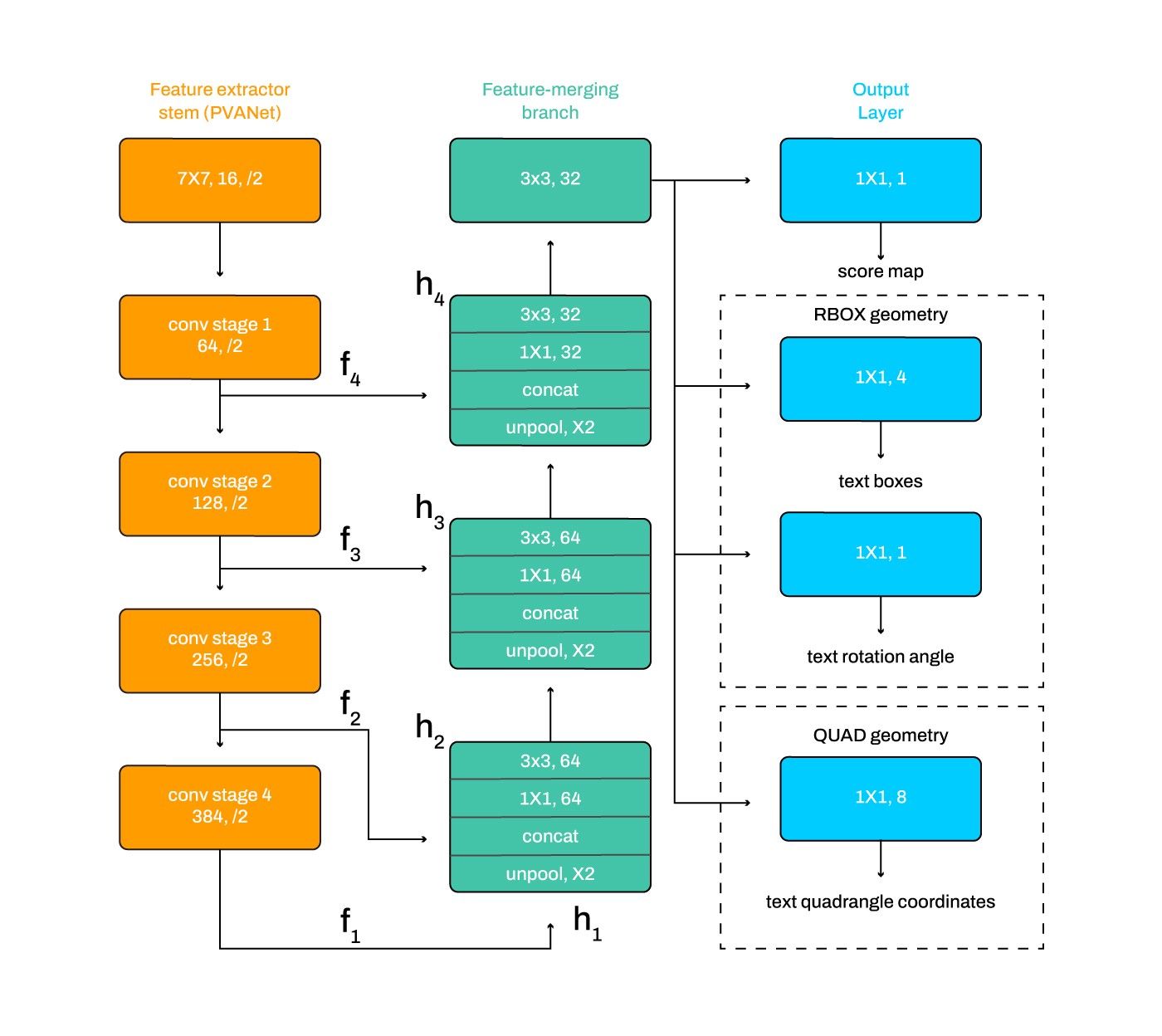
The model directly predicts words or text lines of arbitrary orientations and quadrilateral shapes in full images, eliminating the intermediate steps (e.g., candidate aggregation and word partitioning) with a single neural network from full images.
The network is trained with two objectives: Predicted score loss and Geometry loss. The predicted-score loss function tries to minimize the inaccuracies in text-region prediction. In contrast, the geometry loss function acts as a regulator so that the model doesn’t get biased towards correcting larger areas of text. We gave equal weightage to the predicted-score and geometry loss functions. Predicted score uses class balanced cross-entropy as the objective function. While geometry loss function uses Intersection-Over-Union loss for scale-invariance. More mathematical details can be found in the original EAST paper [1].
We also adopted a U-shaped architecture to merge feature maps gradually while keeping the upsampling branches small. So, it can directly predict the existence of text instances and their geometries from features at different levels, making it computationally faster and efficient, which is a must-have at our scale.
Though EAST supports both text-line and word-level detection, we chose word-level detection, as the text-line detection approaches are often used for long documents, where there is a consistency between the location of the text detection across documents. However, our data is more sparse and lacks structure. The reason behind this is that the author-signatures, watermarks, and titles are mostly single instances. Varying fonts, mixed fonts, rotations, font size, font style, placements, etc. further make the detection difficult.
The EAST model can detect both rotated and parallel-to-axis boxes by making quadrilaterals around the text-word instances. This is extremely useful in our case, as the content we have often have rotated texts put on by the creator to make the post look attractive to consumers. For rotated boxes, wrt, to the horizontal axis, we use the smallest box that circumscribes the original rotated box as shown in Fig 8.

Once we get the individual word-level text instances, we intend to send them to the text recognition module. Before that, we faced a common problem of the variety of aspect ratios and sizes in our examples. If we were to scale all of them to the same size or even pad them to a larger size, it was very difficult for us to have a consistent model metric of correctness. We resized all crops to a fixed height and scaled the width to solve this problem, maintaining the aspect ratio.
We set a threshold on the width based on the analysis of data and the model’s predictive performance. After that, we either added a zero padding on the right or squeezed the width to the pre-decided threshold disregarding the original aspect ratio.

An example of our approach and its results can be seen in Fig 9. We observed for longer words like इज़हार-ए-मोहब्बत in our case, one-size-fits-all methods lead to wrong recognition in most of the cases. Finally, we crop these boxes from the image and send them to further steps in the pipeline.
Text Recognition
The text recognition step takes the cropped images generated in the previous step as input and decodes it into a sequential string of characters from the character list. Considering the correctness level needed in this one, we used the ASTER[2] model as our recognizer. We also tried other models like CRNN+CTC[6], but found ASTER better suited to our use case.
ASTER performs recognition in two steps, the first being image rectification, which deals with correcting the orientation, design, and rotation of the text. The second one is a decoding step that decodes the images into a set of characters. The rectification step is highly critical to our use case due to our data’s wide variety of fonts, textures, and designs. An example of the effectiveness and need of the rectification step is given in Fig 10.

The rectification network adaptively transforms an input image into a new one, rectifying the text in it. It is powered by a flexible Thin-Plate Spline transformation that handles various text irregularities and is trained without human annotations. It is capable of handling both perspective and curved text images. It does this by modeling spatial transformation as a learnable network layer. The network first predicts a set of control points via its localization network. Then, a TPS transformation is calculated from the control points and passed to the grid generator and the sampler to generate the rectified image.
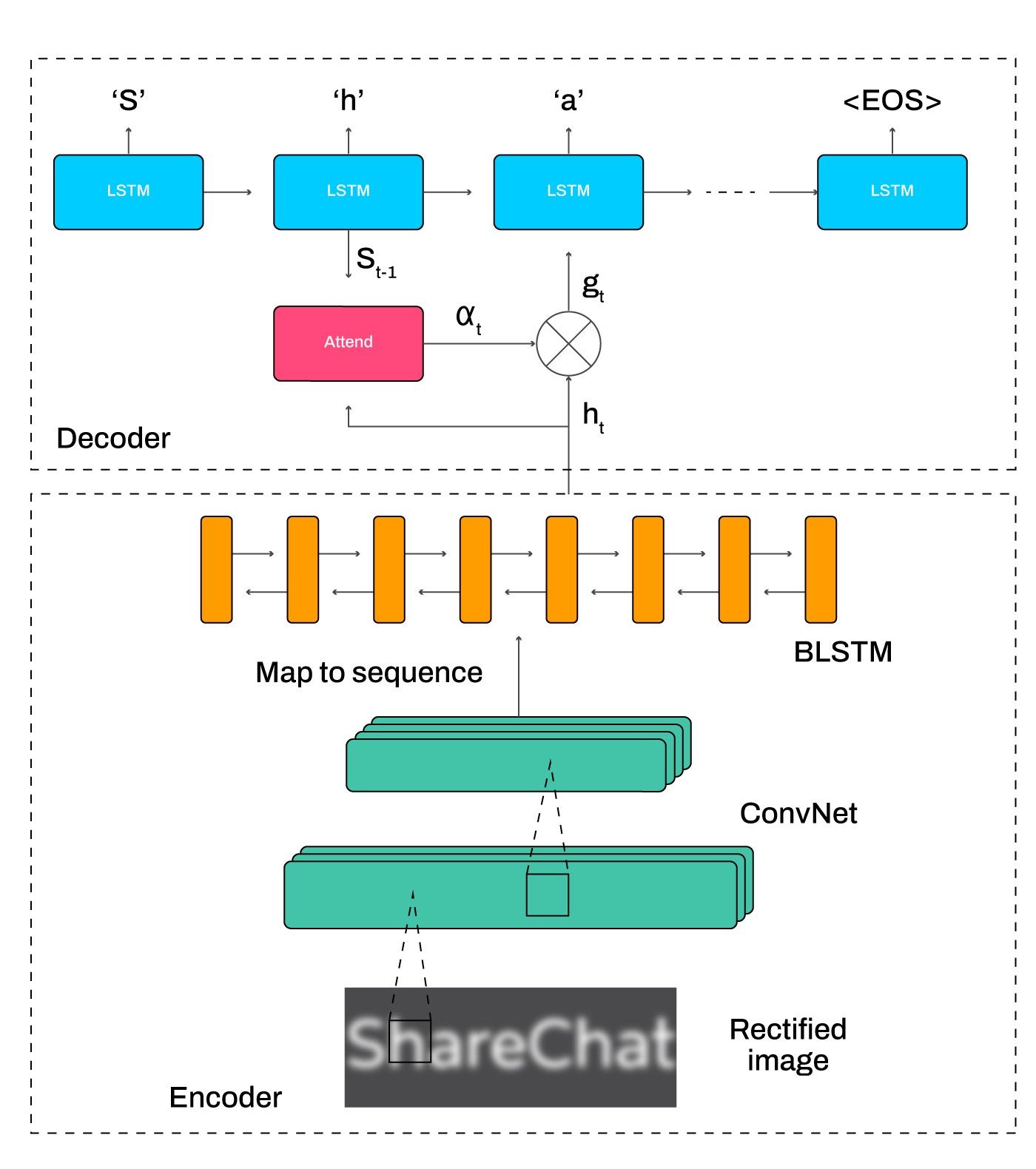
After rectifying the crops, we pass them through a text recognition network. The text recognition network is an attentional sequence-to-sequence model that predicts a character sequence directly from the rectified image. The whole model is trained end to end with the standard CTC loss function[3], requiring only images and their ground-truth text.
The modular architecture of the recognition step similar to what we used is shown in Fig 11. To tackle the recognition problem, we used a sequence-to-sequence model extended by a bidirectional decoder. Since the output of a sequence-to-sequence model is generated by a recurrent neural network, it captures the character dependencies, thus incorporating language modeling into the recognition process.
For generating the character list for the decoder, we set a standard 94 character list for English, which is commonly used for such tasks. This idea is derived from standard decoders of the English language, which deal with 26 small letters, 26 capital letters, 10 digits, and 32 special characters. And this is how we prepared our list. We also developed a character list using the most frequent 94 characters for Hindi, as different scripts vary in number of characters in them. Hence, a combined character list of 2 X 94=188 characters was used.
Conclusion
In this blog, we discussed the challenges faced by our team in developing OCR for our use cases and some of the problems and their solutions. This helped us to setup the baseline for our in-house OCR.
In Part 2 of this article, we will discuss the issues faced due to inaccuracies of the existing text-detection data & algorithms, and how we solved it using an innovative dynamic padding algorithm. We will also discuss how we integrated more languages into our ShareOCR system. Also, we will discuss adding two new modules that help us in weaving these isolated and meaningless regions of text into one single picture and finding what’s relevant for us.
Stay Tuned !
References
[1] EAST(2017) https://arxiv.org/pdf/1704.03155.pdf
[2] ASTER(2018) http://122.205.5.5:8071/UpLoadFiles/Papers/ASTER_PAMI18.pdf
[3] CTC(2006) https://www.cs.toronto.edu/~graves/icml_2006.pdf
[4] Single Shot Detection(2016) https://arxiv.org/pdf/1512.02325.pdf
[5] R2CNN(2017) https://arxiv.org/pdf/1706.09579.pdf
[6] CRNN+CTC(2015) https://arxiv.org/pdf/1507.05717.pdf

