Supercharging ShareChat ML Feature System with Flink DataStream
Md Azmat Ali , David Malinge19 Jun, 2025

1. What Is ShareChat ML Feature System?
At ShareChat, our in-house ML feature system powers personalized feed recommendations across the platform. Built on Apache Flink, it serves as a feature-as-a-service platform for scalable computation, aggregation, and storage of real-time and batch features.
To learn more about the overall architecture and components, check out our previous blog post.
2. Initial design
It's highly configurable via YAML, letting teams define data sources (Kafka, Redpanda, WarpStream, or GCS), feature logic, and sinks (primarily ScyllaDB). A feature serving layer on top of ScyllaDB enables low-latency inference at scale.
Job config example:

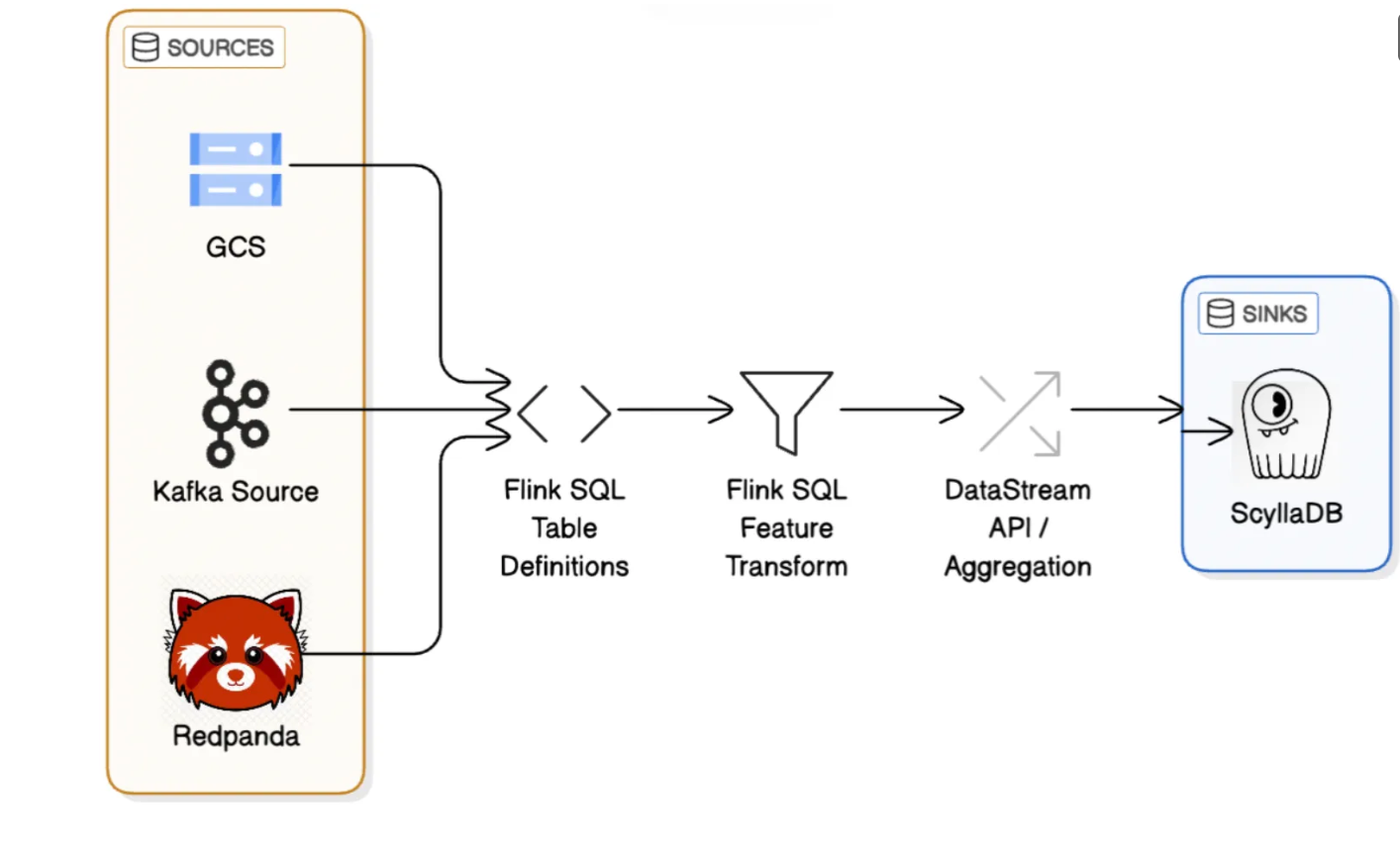
In our original architecture, we leveraged Flink SQL to define and manage the feature computation workflow:
- Source Table Definitions:
We began by defining Flink SQL tables backed by various real-time sources such as Kafka, Redpanda, or file-based systems like GCS. This abstraction allowed us to treat these streams as structured, queryable tables.
- Feature Transformation in SQL:
Using SQL queries on these source tables, we performed business-specific filtering, transformation, and enrichment to derive raw features. This included operations like timestamp normalization, field extraction, conditional logic, and joins all expressed declaratively in SQL. The key benefits are also that SQL offers a number of built-in functions (link docs), is well known as a language and allows software engineers as well as product managers to write and review feature definitions.
- Conversion to DataStream API for Aggregation:
Once we had the required pre-processed features from SQL, we converted the result into a Flink DataStream. This allowed us to leverage the full power of Flink’s programmatic APIs.
In this step, we post-process our SQL changelog to form our in-database representation. Processing data using DataStream API allows us to execute a complex logic, including such things as custom state handling and highly optimized Scylla sink
- Sink to Scylla for low latency access:
The final aggregated features were then written to Scylla, our low-latency, high-throughput storage engine. These features serve as input to our ML models for both training and real-time inference.
3. Benefits of Flink SQL To Create Table
These are some of the reasons initially we used Flink SQL to create table for sources.
- Simplicity & Declarative Syntax
- Writing SQL is concise and readable.
- Plug-and-Play Connectors and Format Support
- Native support for Kafka, filesystem (GCS), and formats like Avro, JSON, CSV, etc.
- Easier onboarding with minimal deserialization/parsing code.
- Faster Iteration & Prototyping
- Writing SQL queries on top of tables is much faster than setting up full DataStream logic.
- Cleaner Separation of Concerns
- SQL
CREATE TABLElets you separate source definitions from transformation logic. - Makes the pipeline modular, improving maintainability.
- SQL
4. Limitations We Faced with Flink SQL as Source
While Flink SQL provided a convenient and declarative way to define sources in the initial phase, it introduced several performance and operational challenges as our use cases scaled:
1- Uneven Load Distribution During Event Deserialization
When using Flink SQL to consume events from Kafka (or Kafka-compatible systems like Redpanda), deserialization happens within the SQL source operator. This introduces a key performance bottleneck:
- 1-to-1 mapping between partitions and tasks: each Kafka partition is processed by a single thread, so 10 Kafka partitions result in only 10 active threads—regardless of available Task Managers which are the Flink components responsible for executing tasks in parallel on available slots (i.e., threads or CPUs). Unlike Spark, Flink doesn't support virtual partitioning for source operators to scale beyond available physical partitions.
- Reads and deserialization in same thread: when deserialization is heavy because of fat messages(e.g., with Protobuf + Redpanda), a single thread per partition can quickly become a bottleneck. Even with 30 Task Managers, only 10 threads are actively used and others stay idle.
- This results in a significant imbalance in resource usage, leading to increased latency and reduced throughput.
- While increasing the number of Kafka or Redpanda partitions might seem like an easy solution, it's often not feasible in practice. Many of our data sources are widely shared and standardized, making partition changes difficult. Moreover, adding more partitions introduces coordination and operational overhead within the Kafka or Redpanda cluster. And importantly, not all source types—like file systems supports partitioning at all, so this approach doesn’t generalize well across all inputs.
2- Source operator State Recovery Flink SQL abstracts away the underlying source operator, which restricted our control over state recovery. Even with savepoints, when the SQL code changed we couldn’t recover source operator state since Flink SQL controls it and would generates new operator IDs based on the query plan. In our case, loss of state became especially problematic for the following types of sources, leading to issues not just in performance, but in correctness as well:
- File-based Sources (e.g., GCS):
Some of our jobs monitor and read files from a GCS bucket. Any changes could cause the job to re-read all the files from scratch. Without granular state management, this led to redundant processing and increased costs.
- Kafka-based Sources:
For streaming sources like Kafka, Flink SQL would resume reading from the last committed offset (committed after last checkpoint). Although this usually resulted in reprocessing a small number of messages, it still introduced data duplication and slight inaccuracies especially problematic in jobs requiring high precision or exactly-once semantics.
3-Lack of Fine-Grained Observability
SQL-based pipelines made it harder to trace per-record behavior during ingestion or monitor custom metrics.
We couldn’t easily plug in prometheus counters, histograms, or logs at the ingestion level for debugging purposes.
For example, assume we received a corrupted msg, this would cause an exception in the flink job during deserialization and would result in the restart of the job. To avoid this, one can set the protobuf.ignore-parse-errors in Flink SQL. This would ignore such error but without any observability.
5. Solution: Migration to Datastream
To address the limitations we faced with Flink SQL sources, we decided to migrate to the Flink DataStream API for source ingestion. This shift gave us the low-level control and flexibility needed to scale effectively and improve observability.
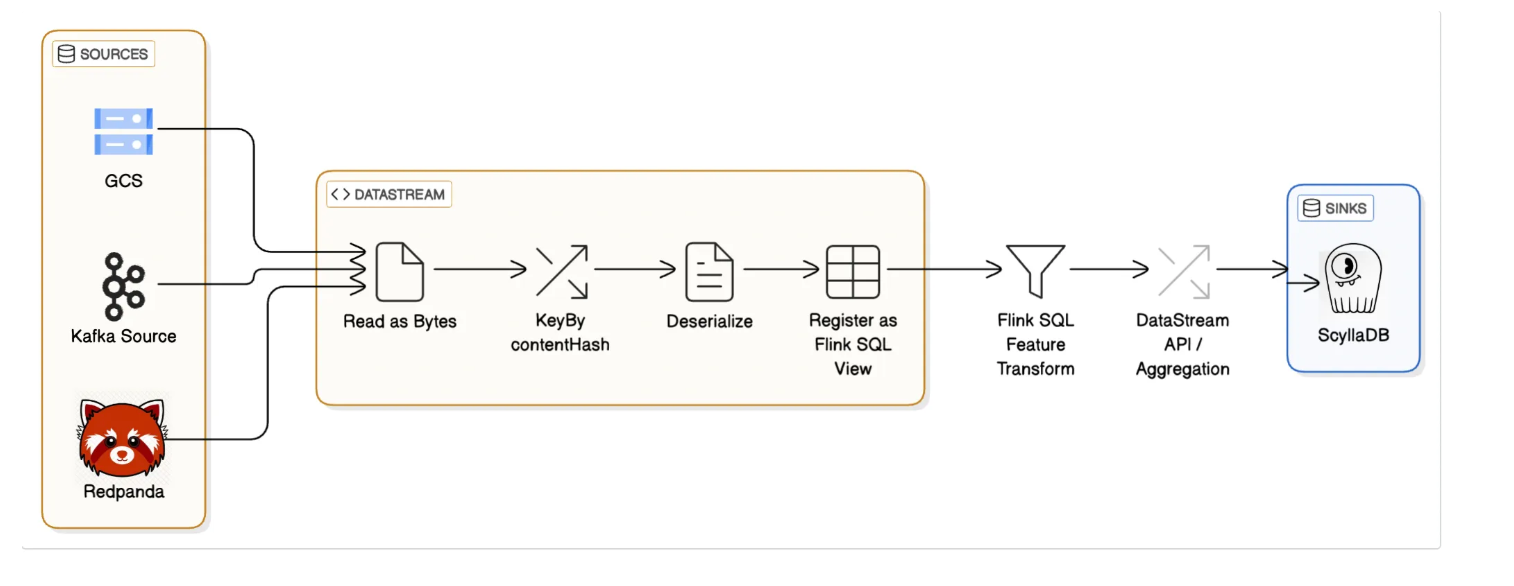
1. Rearchitecting Ingestion: ByteStream-Based Deserialization with DataStream API
One of the most critical changes in our migration was rethinking how data is read and deserialized. Instead of relying on Flink SQL to deserialize events directly in the source operator, we transitioned to a raw byte ingestion model using the DataStream API.
1.1 Ingesting Raw Bytes from Source Systems
We now consume raw bytes directly from the source—whether it's Kafka, Redpanda, or distributed file systems like GCS—resulting in a datastream of raw bytes. This shift gives us full control over how and where deserialization occurs in the pipeline.
To support this, we did a custom implementation by extending Flink's DeserializationSchema. This allows us to keep the source operator lightweight and fully decoupled from any format-specific logic.
1.2 Intelligent Shuffling for Balanced Deserialization
Deserialization is often the most CPU-intensive part of the ingestion pipeline. In the earlier SQL-based design, this step was bound to the source operator, leading to a bottleneck especially when the number of Kafka partitions was small relative to the number of Task Managers (TMs).
Now, after reading raw bytes, we needed to ensure efficient deserialization by uniformly distributing records across all Task Managers. Since there was no natural key available at this stage, we computed a hash of the byte payload and used it as the key in a keyBy operation for shuffling.
For e.g:
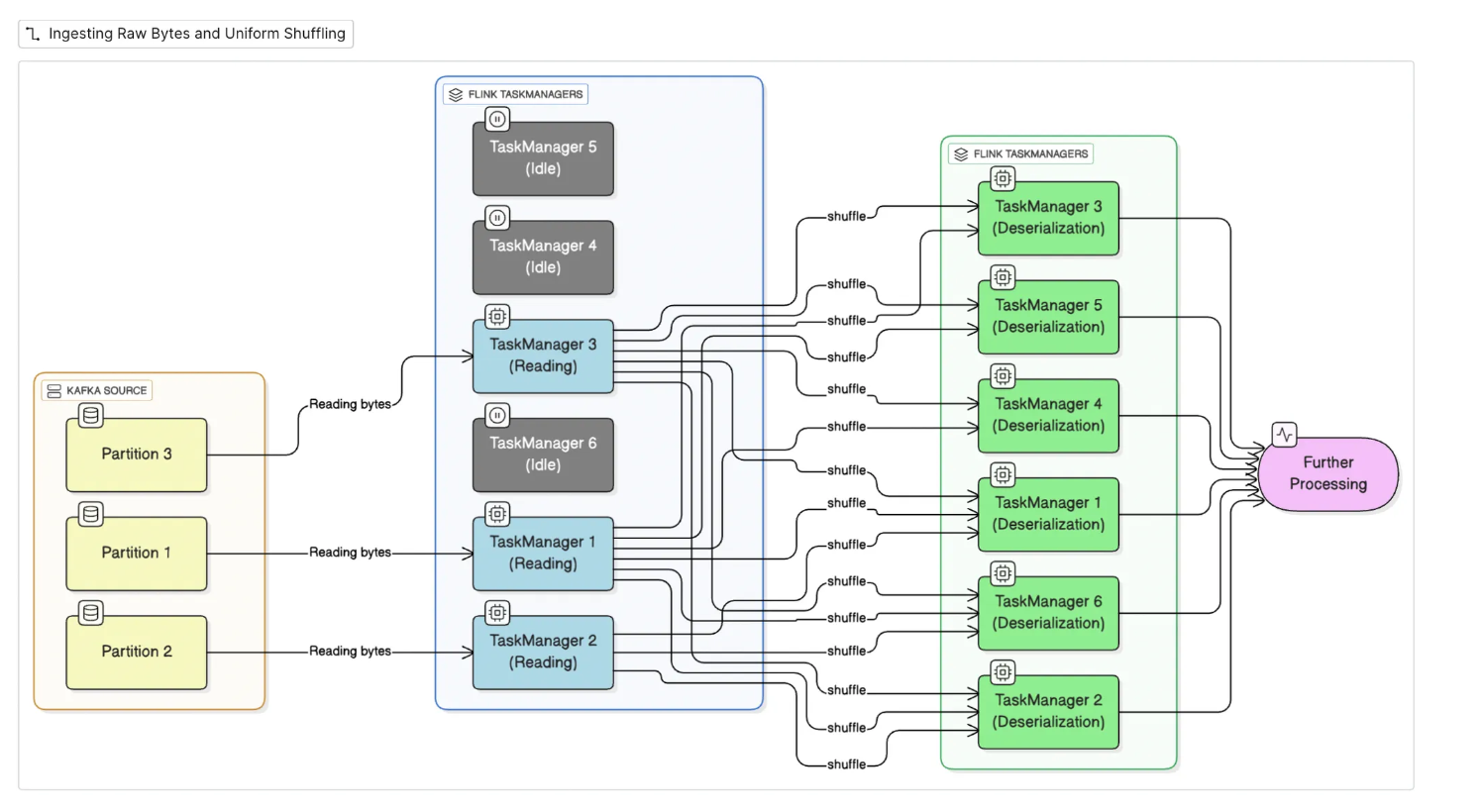
This step shuffling records evenly across all available TMs, ensuring that:
- The deserialization workload is parallelized.
- All compute resources are utilized effectively.
- Throughput and stability improve significantly under high data volumes.
1.3 Flexible and Extensible Deserialization Logic
Once the data is distributed, we can deserialize. We’ve implemented pluggable deserializers for multiple formats including Protobuf, Avro, and JSON.
1.4 Seamless Integration with SQL Transformations
After deserialization, the resulting stream is registered as a Flink SQL view, allowing us to retain the benefits of SQL-based transformations (e.g., feature computation and filtering) on top of a highly optimized ingestion pipeline.
This hybrid approach DataStream for ingestion + SQL for transformation offers the best of both worlds: operational flexibility, scalability, and declarative feature logic.
This restructuring is at the heart of our migration—it resolved our scaling bottlenecks, improved observability, and set the foundation for future extensibility of our ML feature system.
1.5 Real-World Impact: Better Resource Efficiency
This restructuring has had a significant impact on resource efficiency. By offloading deserialization from the source and evenly shuffling records across Task Managers, we ensure that all available compute resources are utilized effectively.
As a result, our ingestion jobs require 20% less cores on average, even under high throughput.
This is due to more uniform compute and better CPU utilization across task managers. This optimization not only improved cost efficiency but also enhanced the stability and scalability of our jobs - critical for real-time systems handling millions of events per minute.
2. Source Operator State Recovery
In Flink, every operator in the job graph whether it's a source, transformation, or sink—is assigned a unique Operator ID either manually if possible or generated by flink. These IDs are used internally to map operator state during savepoint restoration. If an operator’s ID changes between job versions (e.g., due to code refactoring or implicit ID regeneration), Flink may not be able to map the saved state back to the operator, resulting in state loss or restore failures.
When using the DataStream API, we gain explicit control over these IDs by assigning stable and deterministic operator UIDs. This is especially important for source operators, which typically maintain offsets within input streams and must recover accurately on job redeployments.
2.1 Assigning Stable UIDs for Source Operators
We assign a deterministic UID to each source based on its Kafka topic and consumer group name. This ensures that the source operator retains the same identity across deployments, allowing Flink to restore its state accurately from savepoints.
Other non-source operators in the pipeline (such as SQL transformations) are assigned dynamic UIDs to avoid conflicts during savepoint restores. For this, we introduced a custom variable called startTimeMillis, which is embedded into operator IDs to ensure uniqueness per deployment.
You can see an example in our job configuration:
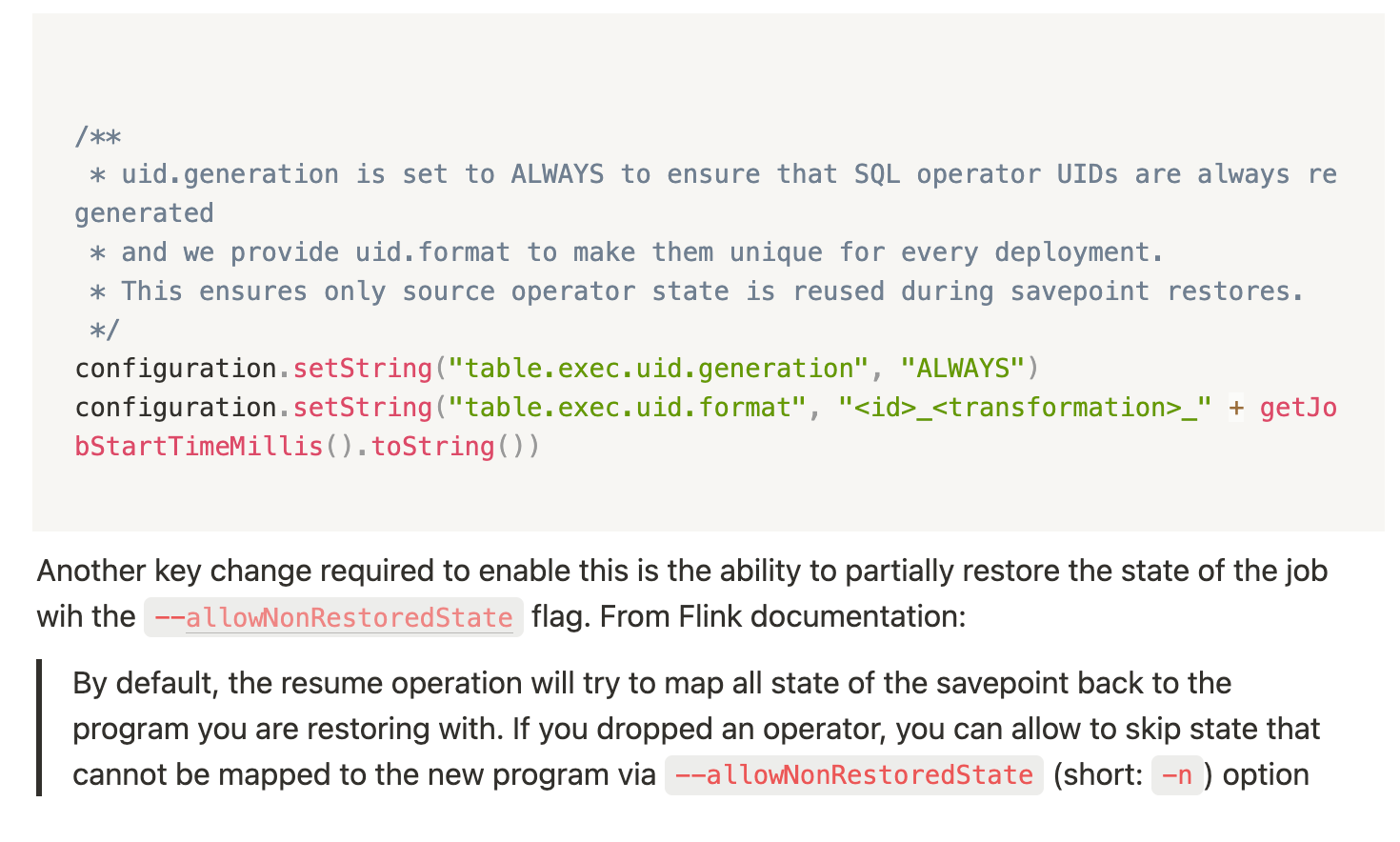
By decoupling source state from SQL logic and maintaining deterministic operator IDs, we’ve significantly improved the reliability and operational efficiency of our stream processing jobs.
This setup brings several advantages:
- No redundant file reprocessing for batch/file sources
- Kafka offsets are resumed accurately, avoiding reprocessing or data loss
- Faster restarts and rollbacks, especially valuable during production incidents
3. Fine-Grained Observability with Custom Instrumentation
Switching to the DataStream API gave us the flexibility to introduce per-record observability and robust error handling right at the deserialization step, something that was nearly impossible with Flink SQL.
Since we now control deserialization we can handle errors and collect metrics.
This change was crucial for debugging production issues. Instead of silent drops or job restarts, we now get real-time visibility into schema mismatches, corrupt messages, or upstream data issues.
In addition, we can instrument any downstream processing step with metrics for example:
- Event age/freshness
- Custom counters for data quality checks
- Histograms for payload sizes or processing latencies
With this level of observability, we’ve been able to move from reactive debugging to proactive monitoring, significantly reducing MTTR (Mean Time to Recovery) when issues occur in production.
6. Post-Migration Wins in DataStream Ingestion
While migrating to the DataStream API helped us overcome several limitations, it also opened up new possibilities for cleaner designs and operational improvements. Because our initial sources processing is isolated, we can now perform generic operations on the sources.
For example, two capabilities we have quickly added:
- Cutoff filtering by event time (consume until or from a given time)
- useful for seamless source migrations.
- Sampling records
- allows running lightweight test or debug jobs without consuming full traffic and costing much less.
In Flink SQL, these kinds of operations had to be embedded deep in transformation logic, making queries verbose and error-prone. With the DataStream API, they’re just simple, configurable filter steps post-deserialization.
This pattern makes the ingestion layer more powerful and extensible. Going forward, we can build richer features like:
- Entity-aware sampling (e.g., by user ID, post ID and request ID)
- event-type–specific filtering
- Feature-level debugging
We’ve only scratched the surface of what this model can enable.
7. Conclusion
Migrating from Flink SQL to the DataStream API has been a foundational shift for our ML feature system. While SQL gave us a quick and clean start, we eventually hit the above limitations.
The tradeoff of adding more boilerplate and complexity was worth it. Today, we have an ingestion platform that’s not only cheaper but also more reliable and debuggable and better aligned with the evolving needs of our real-time ML infrastructure.
If you're hitting the limits of Flink SQL and wondering whether to switch to the DataStream API, our experience suggests it’s worth the investment—especially when observability, operational flexibility, and resource efficiency matter.

