Building a Unified Events Platform at ShareChat
Anshul Khemani, Nilesh Kevlani, Rushabh Shroff17 Mar, 2026

At ShareChat's Central Data Platform (CDP) team, we handle more than 1,000 different event types across 5 apps, ingesting upward of 80 billion events per day. At peak, our Kafka cluster handles more than 2 GB/sec of compressed throughput. Every user interaction — a video play, a share — flows through our event infrastructure and eventually lands in the warehouse, feeding dashboards, ML models, and product analytics.
Managing this at scale is hard enough. Managing it across 1,000+ event types, each with its own schema, owners, and consumers, is a different class of problem. For a long time, event onboarding was a multi-step error prone process, and it was slowing us down.
This post is about what we built to fix that.
Problems with The Legacy System
With the legacy system, onboarding a new event into production meant touching multiple disconnected systems.
We had four separate services:
- Warehouse Schema Manager (WSM). WSM stored table contracts and metadata in a GitHub repo.
- A legacy event management system. It stored event metadata — names, IDs, Kafka topic names.
- Our central protobuf contract registry. Users needed to onboard protobuf contracts here and use them for publishing data.
- Ingestion system. This place used to hold configurations for the ingestion system.
These four were loosely linked by event name / event ID, which was as fragile as it sounds.
In practice, this meant:
- Kafka topics for dedicated events had to be manually provisioned by the data platform team.
- Any schema change meant editing WSM by hand, raising a PR, getting it approved, and deploying via Spinnaker.
- A bad deployment blocked the entire pipeline for everyone in the org.
Starting 2025, ShareChat's focus shifted from cost optimizations to building new revenue streams. Product teams needed to ship fast, and our tooling needed to get out of their way.
What We Set Out to Build
We wanted Event Management System (EMS) where any engineer at ShareChat could:
- Define an event schema once — and have it automatically propagate to Kafka, BigQuery, and Delta Lake.
- Produce events in whatever way made sense for producers’ stack — gRPC, direct Kafka, or HTTP.
- Own and discover events through our Internal Developer Portal based on Backstage, Atlas — with clear ownership, role-based access, and discoverability baked in.
- Trust that the same Protobuf contract governs both the Kafka topic and the warehouse table.
Architecture Overview
When an user registers a new event on Atlas, EMS fans out and provisions everything that event needs — in one shot.
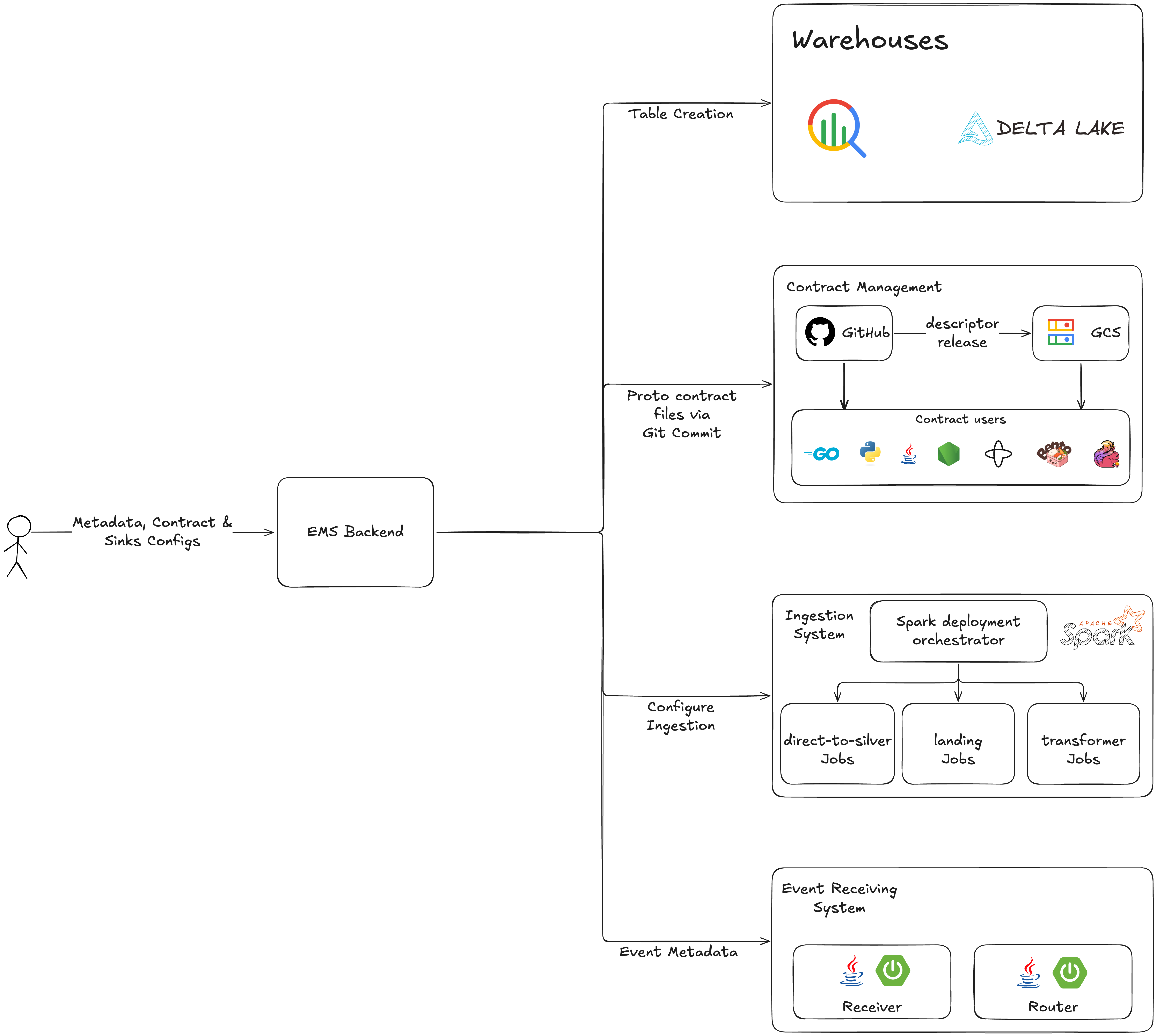
The architecture breaks down into four concerns:
- Protobuf contract management
- Sink setup — Kafka, BigQuery, Delta Lake
- Event production — three paths to Kafka
- Ingestion — from Kafka to the warehouse
Let's go through each.
1. Protobuf Contracts: One Schema to Rule Them All
The contract is the foundation of everything in EMS. Every event is defined as a Protobuf schema, and that schema is the single source of truth for both the Kafka message format and the warehouse table structure.
This matters more than it might seem. Before EMS, Kafka schemas and warehouse table definitions lived in separate systems and could drift out of sync — silently. A field typed int64 in Protobuf mapped to a 32-bit int in Delta Lake would cause ingestion failures that were painful to fix. With a single contract governing both, that class of bug goes away entirely.
Creating a contract
Engineers have two paths:
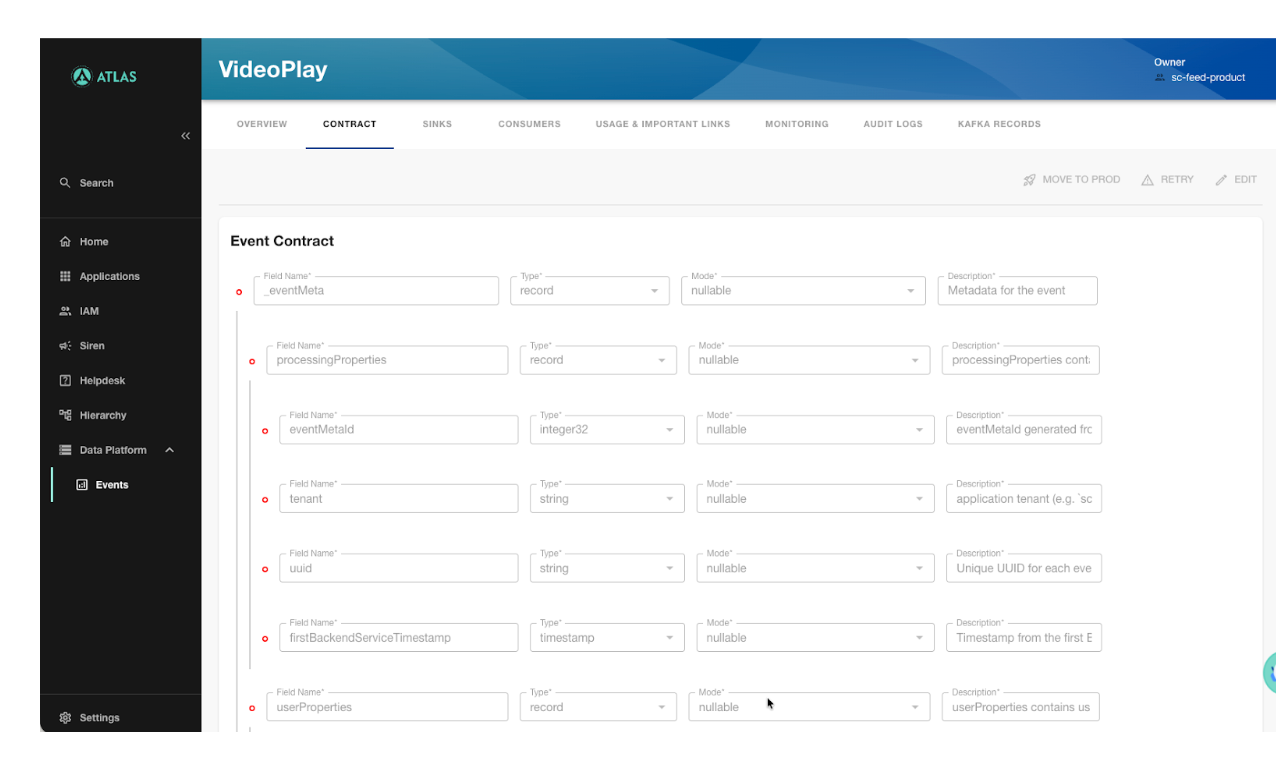
UI-driven: For most use cases, engineers fill out a field-by-field form in Atlas — field name, type, mode (nullable/required), and description. EMS generates the .proto file automatically.
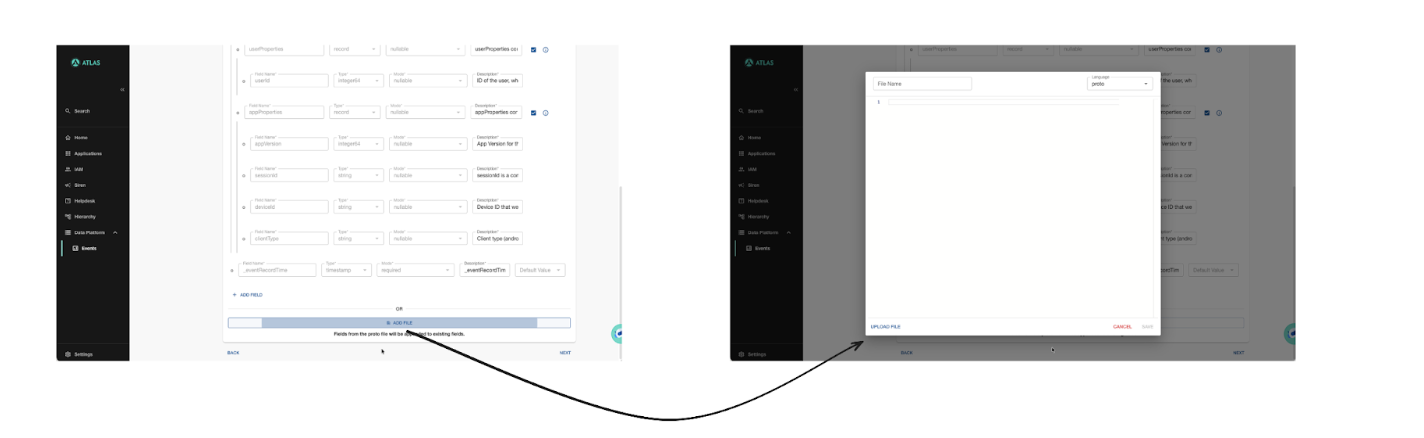
Raw .proto upload: Teams with complex schema requirements write .proto files directly and upload them. Both paths lead to the same place: a validated, registered contract.
Regardless of which path an engineer takes, platform-level fields are always injected. This ensures consistency across all 1,000+ events in the org without anyone having to think about them.
Schema evolution
Fields can be freely modified while they are in Staging — including backward incompatible changes. Till this point, resources are created/updated in the staging environment, so it is okay to make backward incompatible changes. Once a field moves to Production, all resources are created/updated on the production environment as well. Backward incompatible changes are no longer allowed after this. This gives teams room to iterate during development while protecting downstream consumers from breaking changes once data is live.
Distributing contracts
Once registered, the .proto files are committed to GitHub. From there, two distribution paths run in parallel:
- Consumers that need the raw proto contract pull from the GitHub repo using our in-house tooling.
- A descriptor release pipeline compiles and publishes binary descriptor files to GCS, for consumers that need dynamic deserialization without code generation.
We'll cover the full mechanics of this distribution system in a follow-up post.
2. Sinks: Kafka, BigQuery, and Delta Lake — All From One Place
Once a contract is registered, EMS automatically provisions all the data destinations — what we call sinks.
The creation flow
Every event starts in Staging. Staging sinks are created first, giving teams a safe environment to validate the event end-to-end before anything touches production. When they're confident, a single "Move to Prod" action replicates the full setup in Production.
What a sink looks like
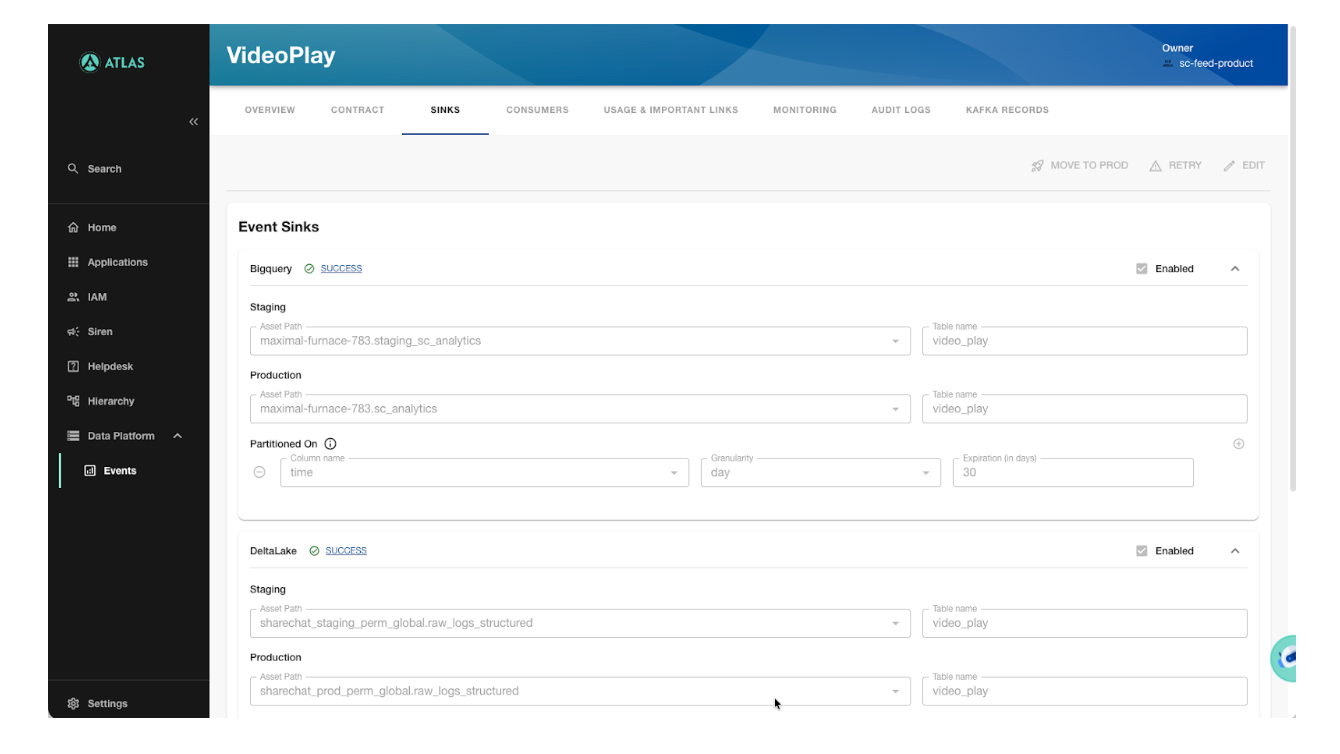
Error handling
Sink creation is designed to be resilient. If one sink fails, that sink's status is updated in our database and the error is logged — but the rest of the event creation continues. A sequence of actions is also followed when doing this, for example, if protobuf contract sync to GitHub is failed, then sink setup is skipped as they can not function without contracts being available. Failed or skipped sinks can be retried independently from the UI, without affecting the other resources provisioned for that event.
Kafka access control
EMS manages Kafka topic access through WarpStream. Credentials are scoped per team — when onboarding new events, engineers can use credentials available to their team directly through Atlas.
3. Producing Events: Three Paths to Kafka
We deliberately chose to support multiple production patterns rather than a single one. Different teams have different needs — latency requirements, stack constraints, client type — and forcing everyone into the same path would have created as many problems as it solved.
gRPC via CDP
The recommended path for backend services. Teams call a gRPC endpoint maintained by the CDP team. It handles contract validation, and Kafka routing. Kafka is completely abstracted away. Producers do not need to maintain credentials on their side.
Direct Kafka production
For teams that need lower latency or more control, EMS vends Kafka user credentials that let producers write directly to topics using the standard Kafka API. Credentials are managed through Atlas.
HTTP / Frontend events
Frontend clients send events as JSON over REST. Our receiver service accepts the JSON payload, converts it to the registered Protobuf format, and publishes it to Kafka.
This conversion — from generic JSON to Protobuf at scale, for 1,000+ contracts, without per-event custom code — is a non-trivial problem. As existing solutions for this did not work for us, we built a generic conversion layer using Protobuf descriptors. The converter polls GCS for descriptor updates, so newly onboarded events are automatically handled without any deployment or restart. We'll cover the full implementation in a separate post.
In all three production paths, the same Protobuf contract governs the event shape. Downstream consumers — streaming jobs, warehouse tables, ML pipelines — always see a consistent schema.
4. Ingestion: From Kafka to the Warehouse
The Ingestion Coordinator handles getting events from Kafka into the warehouse. When an event is registered, it automatically sets up the right Spark jobs based on the event's configuration:
- Streaming — Spark Structured Streaming jobs run continuously for latency-sensitive events. Data directly goes to the target table.
- Batch — data from multiple topics first goes to a single intermediate table and from there, scheduled jobs consume on a configurable cadence for high-volume or cost-sensitive events.
The ingestion jobs use the Protobuf contract provided by EMS, so schema changes registered in EMS automatically propagate to the ingestion layer. No manual table alterations, no separate PRs.
5. Discoverability and Ownership via Atlas
A self-serve platform is only as good as its discoverability. EMS is deeply integrated with Atlas, our Internal Developer Portal, and that integration covers three things: ownership, access control, and search.
Every event has an owner — a pod and a team — visible on the event page and in the org-wide events list. "Who owns this event?" goes from a Slack thread to a one-second lookup.
Access control in Atlas is role-based. To edit an event, an engineer needs the appropriate role for the pod that owns it. This keeps ownership meaningful — teams are accountable for their events, and changes can't be made by just anyone.
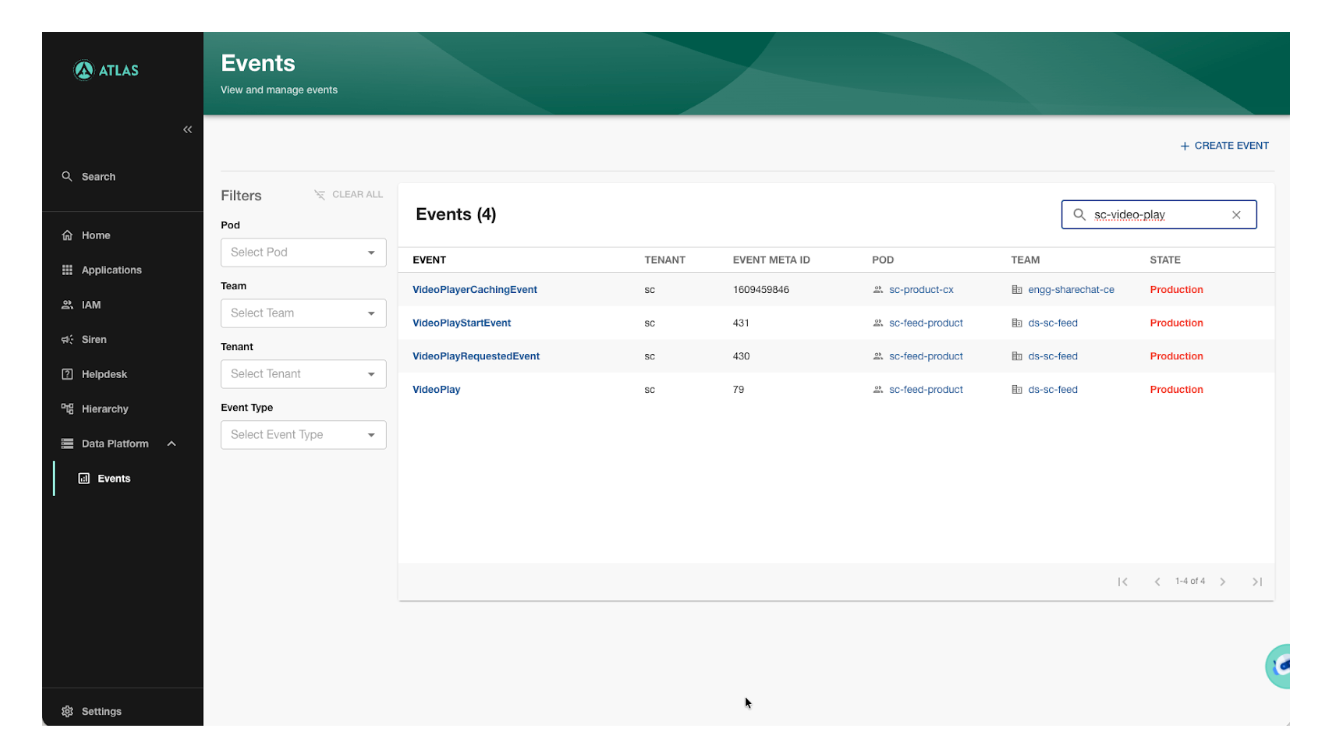
Each event page has tabs for all the important details about an event that users might need — Contract, Sinks, Consumers, Usage & Important Links, Monitoring, Audit Logs, and Kafka Records. Everything related to an event, in one place.
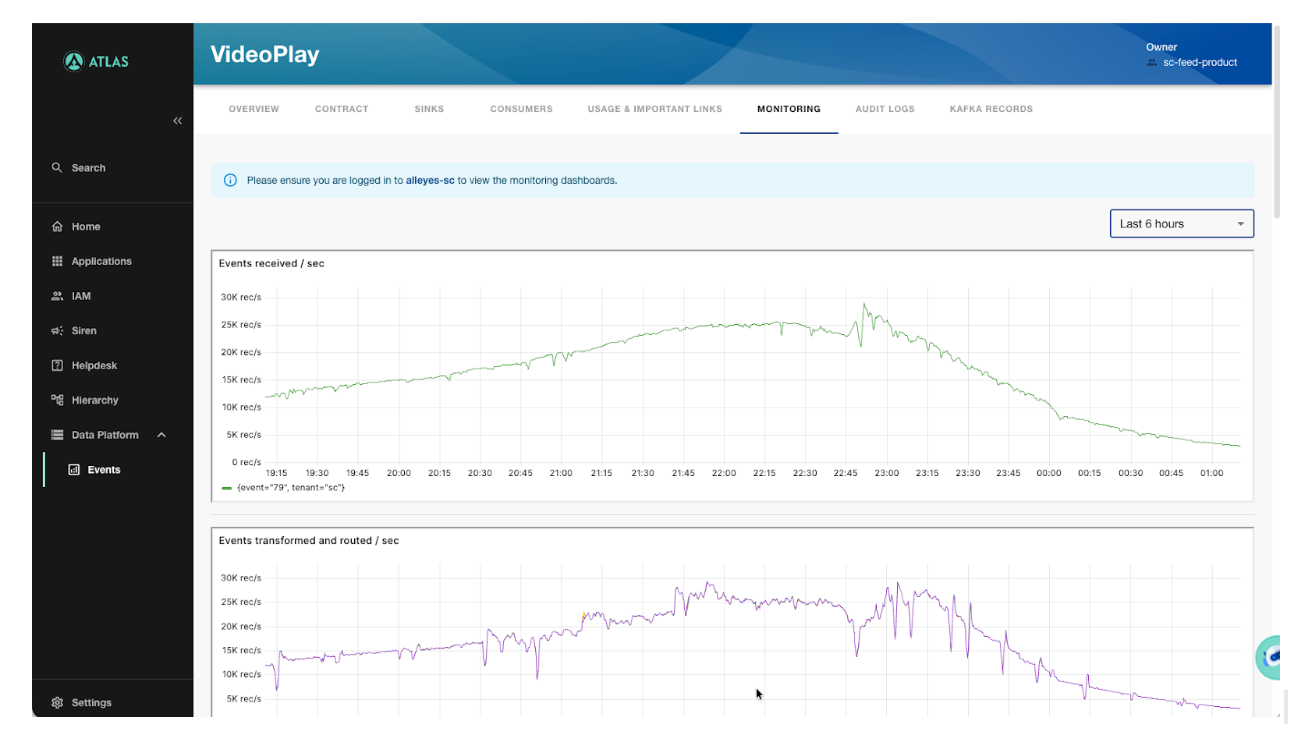
6. Observability
At 80 billion events a day, you need to know immediately when something is wrong. EMS surfaces per-event monitoring directly in Atlas — no need to navigate to a separate tool.
Wrapping Up
EMS replaced a set of fragile, manually-operated tools with a platform where any team at ShareChat can define, produce, and consume events — without waiting on us.
The core idea was simple: make the Protobuf contract the single source of truth, and treat everything else — Kafka topics, warehouse tables, ingestion jobs, access control — as automatic consequences of registering that contract. That shift is what let the system scale to 1,200+ events across the org, while actually reducing the load on the CDP team rather than growing with it.
This is part of a series on how we modernized ShareChat's events platform. Next up: how we built a generic JSON-to-Protobuf conversion layer for 1,000+ contracts without a single line of per-event code — and how we distribute Protobuf contracts to producers and consumers across the org.

