Evolving Event Streaming Architectures - Nx scale at one-third of the cost
Anuraj Jain, Ivan Burmistrov, Arya Ketan24 Jan, 2024

In this post, we discuss the evolving architecture for ShareChat’s event streaming platform. We’ll deep dive into our first-generation architecture, including what problem statements we constantly faced with it and strived to solve. We’ll also cover what parameters we evaluated for different technologies and what made us choose Redpanda over other streaming data solutions.
Lastly, we’ll share what our next-generation architecture looks like and what the future holds for us in this space.
How it started: ShareChat’s event streaming architecture
Let's look at our first-generation architecture for the event streaming platform.
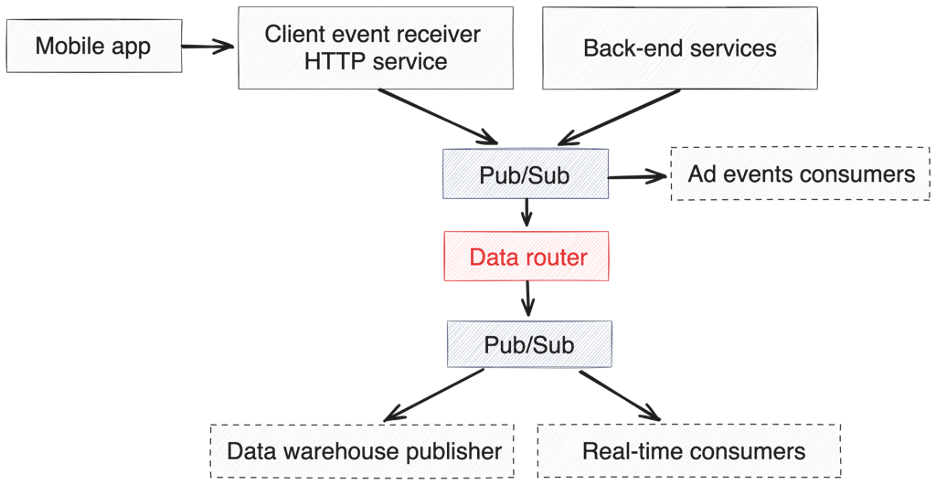
Diagram of ShareChat’s architecture for the event streaming platform
As you see, event streaming is at the heart of
- All user engagement events (and hence product analytics)
- Ads funnel analysis
- Input for feature store & embedding store for our recommendation system AI algorithms
At peak, this system saw a combined throughput of 20 Gbps and ~15 million messages per second. What supported this impressive scale was the extreme elasticity of Google Pub/Sub and the system’s support for polyglot languages.
Chinks in the armor
While Pub/Sub gave us tremendous agility to build products, over time, we realised that its core functionality was inefficient with some of our other critical systems.
For example, with the out-of-the-box available Pub/Sub connector for Flink, the flow is rather not ideal. Apache Flink® sends Pub/Sub acks only after completing the checkpoint, which leads to the following set of problems — if you set the ack deadline too low, you get the risk of frequent re-sends and hence duplicates. If you set the ack deadline too high, you risk some messages being processed for too long (the consumer gets the message and dies, then the next consumer will get the message again, but only after the ack deadline interval). Basically, you can't win in this model.
For Pub/Sub, the max ack deadline is 10 minutes, which is risky for complex jobs since checkpoints can easily take much longer. And, when this happens, you'll get an infinite loop of ack expirations and resends.
Additionally, Pub/Sub has ordered processing support, and we have to create a separate subscription for ordered messages. Messages with duplicate keys might not be guaranteed on the same consumer/subscriber pod (it does best effort delivery to the same subscriber but does better load balancing), whereas with Apache Kafka®, unless the partition number is not changed, ordering is guaranteed. (Here’s a good explanation of Google Cloud Pub/Sub ordered delivery).
Another challenge was the inefficient batching. For the producer and consumer, each message has to be compressed individually and batched. The compression in the Pub/Sub client is actually compression (only Gzip) over gRPC and helps to reduce networking costs. However, please note that this does not help reduce Pub/Sub cost (basically, throughout, it will still be measured with original uncompressed bytes). Finally, this is available only to Java and C++ clients, and we have the majority of our applications in Golang and Node.js.
At our scale and volume of events, these inefficiencies started impacting our cloud costs, directly leading to massive GCP bills. And, since Pub/Sub is a proprietary system without an open source component, there’s limited visibility and understanding of errors when something goes wrong.
So, what about Kafka?
For each problem statement mentioned above, three answers resonate Kafka, Kafka, and Kafka.
Most of us are now extremely familiar with Kafka technology, so we won’t dive into the pros and cons covered by countless other blogs. Instead, let's delve into the underlying principles we wanted to adopt in choosing the right technology and why we chose Redpanda as our Kafka-compatible system.
- Kafka-API compatibility: We love Kafka and the ecosystem that has flourished. Currently, using any other API is simply shooting ourselves in the foot (like we did with Pub/Sub).
- Data is processed locally to our network and compute: With Redpanda’s BYOC deployment, data remains within the realms of our infrastructure boundary, which makes us sleep better. It keeps our data protected against changing data compliance requirements without worrying about large volumes of work later on.
- High-throughput performance: In the cloud, underutilising resources means gifting money to the hyperclouds. Software that can scale and saturate hardware is the type of software we look to work with. Thread-per-core architecture is something that has truly worked in saturating hardware and is observed intricately by us as long-term users of ScyllaDB.
- Reliability-engineered and delivered: Redpanda offers several advantages here.
- Tiered Storage. Server nodes in the cloud are like a Houdini act— extremely ephemeral. When a server node goes down, typically, large-scale data movements happen to bring a Kafka cluster back to stability. Tiered Storage gives the flexibility to have relatively small hot data in the cluster, thus improving the recovery time for a lost node.
- Zero data loss. Raft works. Period.
- Hands-off reliability engineering. We wanted our engineers to focus on our product and tech platform problems. Spending countless hours in reliability engineering on Kafka infrastructure is best left to the experts. Redpanda Cloud’s fully managed service frees our engineers to focus on the right things.
- Observability: we love it, don't you? Having a very rich set of metrics available for each topic and consumer and being able to quickly understand production and consumption patterns from a single pane leads to 10x developer productivity.
- OSS-first and cloud-agnostic: Our long-term architectural goal is to have a poly-cloud architecture; with our evolving scale, we believe that is how we will drive maximal efficiency. Therefore, the event streaming solution should be able to work on any commodity hardware and should have an open source/source available offering.
With all the requirements firmly trenched in, our engineering troops hunted for solutions, and guess what? Redpanda fell right into the solution basket, ticking all the boxes.
The moment of truth: migrating to Redpanda
We divided our event streaming architectural evolution into three phases: proof-of-concept, onboarding, and scale-up. Let’s review each of these and what we did.
1. Proof of concept (POC)
While Redpanda seemed impressive on paper, the proof is in the pudding. So, our POC goals were to establish a performance benchmark against our top use case and a resiliency check via chaos emulations. To achieve these, we set up the following test:
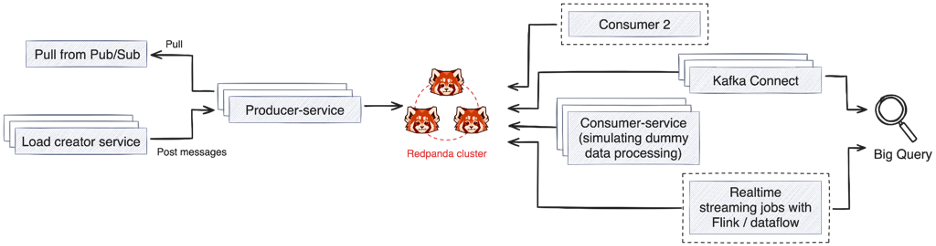
Result summary for different types of tests
- Load stress tests a cluster to up to 1 GBps production rate and 1 GBps consumption rate with 1 consumer group. We did not face any issues in reading/writing at this scale.
- The noisy neighbour test is done by having 2 consumers, one consuming 5x the scale of another consumer. An easy way to test this is to start 1 consumer from the latest and another consumer from the earliest offsets on a topic that contains lots and lots of data.
- We verified that even after adding 5-6 heavy consumer groups, we did not see any latency or consumption rate issues for other consumer groups caused precisely by noisy consumers. However, with the load increasing on the cluster, produce and consume latency was observed across all topics and all producers and consumers.
- Stress the CPU on brokers to 95% utilisation.
- As message load increased on the cluster and CPU utilisations reached 95%, producer and consumer latency increased. This indicated that this is the CPU limit beyond which the cluster needs to scale up.
- Fault-tolerant test by emulating
- Our objective for this test was to inject failure in the cluster by deleting a pod or downscaling/deleting a node or all nodes from a zone and then observing how the producers and consumers react to the failures.
- Our objective for this test was to inject failure in the cluster by deleting a pod or downscaling/deleting a node or all nodes from a zone and then observing how the producers and consumers react to the failures.
During these tests, we observed that, as per expectations, there were errors in producing and consuming when the pod or node got deleted, but normalcy returned after the restoration of the pod/node. One outcome of these tests was that we found a bug (fixed in v23.1.16), which was promptly fixed by the Redpanda engineering team.
Most importantly, there will be errors during the window, but on restoration of the resource, one should expect normalcy to return.
- Accuracy test by matching producer and consumer data set
- We had a 100% validation rate for the messages produced during the test. We produced ~80 million messages and validated these during the test.
2. Onboarding
Given the positive feedback from the proof of concept, we created an exhaustive roadmap for onboarding to fully manage Redpanda BYOC. The following worked as part of our onboarding process.
- Brown bag sessions with the larger development team to educate teams about the Redpanda evaluation and the benefits we saw.
- ROI justification to leadership for moving to Redpanda in terms of
- Articulation of cost savings. We could project millions of dollars of cost savings annually at our scale.
- Reliability engineering test results
- Creation of a center-of-excellence team.
- The purpose of this team was to find and create best practices for the teams. E.g., how to find the best library versions to use in different languages, good default producer and consumer configurations for various load patterns, and code reviews as teams started migrating their existing codebases to Redpanda. Finally, this team helped identify bugs/gaps in the usage and interface with the Redpanda team to bridge them.
3. Scale up
To scale up our Redpanda usage, we identified usage patterns and started migrating accordingly. For example, one of the primary use cases of the message system in our company is pushing data to the data warehouse. Another is real-time data processing over engines like Apache Flink for things like user notification, ad events aggregation, and feature store updates.
So, instead of creating multiple parallel threads at once, we have gone with one use case at a time and stabilised each one before moving to the next. In each use case, we tried to diligently arrive at the optimal configurations to run the entire setup efficiently.
Post-migration lessons learned
While the onboarding and scale-up with Redpanda have been relatively smooth and stress-free, there have been learnings.
- Consumers can lead to hot-spotting. If consumers update their offsets very aggressively (per message) at high volumes, then hotspots in nodes occur. It’s advisable to commit at intervals and have multiple consumer groups.
- Redpanda continually rebalances leaders in the background. Some rebalances might take time, and errors or higher latency might be observed during that window. To overcome this, add bounded retries and higher batching of messages during production.
- Using a TryProduce (encapsulating produce to failure conditions) leads to more stable production as there are chances of latency spikes otherwise.
- For high-volume topics, we retained only a few hours of data in local storage and had longer retention in the tiered storage layer. This helped reduce the volume of data to be transferred on a node failure. Do note that consuming from tiered storage is slightly more expensive for consumers.
- For folks migrating from the Pub/Sub ecosystem to Kafka, optimising the number of connections and tuning configs for partitioning is essential, as Pub/Sub does these under the hood. In contrast, for Kafka/Redpanda, producers must do these configurations themselves.
- Configuration for the producer for UniformBytesPartitioner in the Franz-go Kafka client has to be decided on a per-case basis. It should be based on what request throughput each producer client has, and it affects how frequently clients will switch the connections. The bytes limit parameter in UniformBytesPartitioner should be configured with enough bytes to pin the client Redpanda connection for enough duration.
- Creating multiple Kafka clients is not ideal and creates connection overload. A single Kafka client per consumer or producer per cluster should work fine for most use cases.
Another point to mention is that the support from the Redpanda SRE team has been very impressive. Multiple instances of prompt support, customisation of configuration for our use case, and proactive and reactive maintenance of the cluster.
Result: a low-cost, high-performing, next-gen event streaming platform
A picture repaints a thousand words and lets us show our next-generation architecture for the event streaming platform.
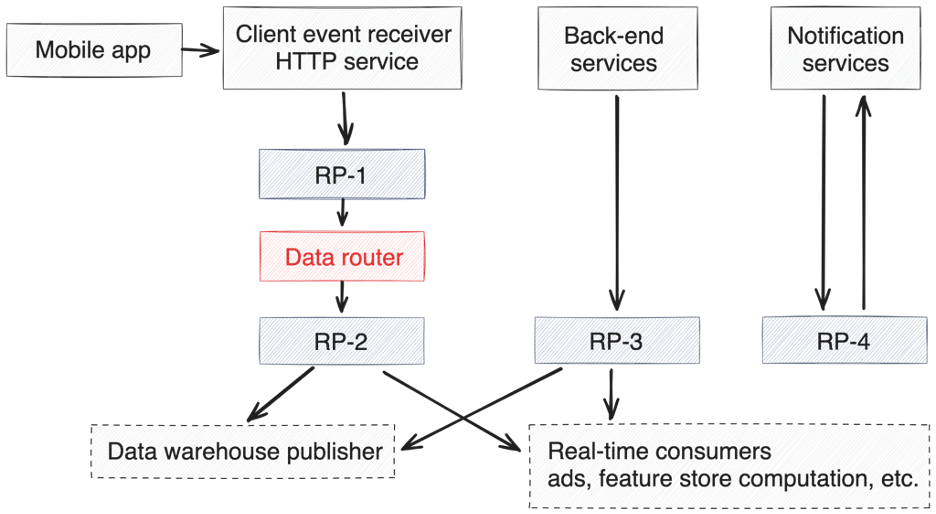
Our new architecture now delivers 3 Gbps at ~5M messages per second, all delivered from less than 40 nodes of 8 core-32 GB machine specification. As a result, we have reduced our cloud infrastructure spend on event streaming by about 70%, resulting in savings of millions of USD annually. We are now scaling up new use cases on our event streaming architecture without worrying about spiralling infrastructure costs.
Our next-gen event streaming and data platform roadmap
Redpanda is now an integral component in our architecture, delivering highly critical use cases, and our roadmap is now turning towards adopting Flink and Spark for our many data processing use cases.
We also eagerly await Redpanda’s WASM-based Data Transforms and Apache Iceberg integration. These innovations will supplement our architecture, and in the future, we will simply point a Spark or Flink job to Redpanda Tiered Storage with Iceberg. And with Wasm data transformations, we can do a lot of low-level data processing on nodes closer to the storage layer.
This is the first in a series of posts on our journey towards a next-generation event streaming and data platform architecture, so stay tuned. If this sounds like fun, and you want to work with awesome people who like to dibble and dabble with challenging tech and scale, come work with us — we’re hiring!

