How we migrated 700+ Million videos in 48 Hours: A journey of data from one cloud to another
Satyajit Singh26 Aug, 2022

How we migrated 700+ Million videos in 48 Hours: A journey of data from one cloud to another
The most critical part of any short-video app is the Users and the short videos, of course. The growth this platform has seen in the past years has been nothing short of exceptional.
In terms of engineering efforts, the amount of data short video apps generate is no joke. Handling, storing and managing such a large amount of data is a challenging task. ShareChat’s acquisition of Mx TakaTak required all this data to be transferred from their Cloud infrastructure to ours in the shortest possible time to bring both universes together.
The Task
The task was simple if explained in layman's terms: move videos from their storage to ours.
Simple enough? Well, not really. As explained above, the size of the data and the time at hand both made the task a little difficult for us. We wanted to migrate the data in the minimum time possible, as this was necessary to start serving data from our new backend. That also blocked the live migration of posts from MX TakaTak to MOJ takaTak as we couldn’t start onboarding users without their videos transferred to their respective accounts in the new app.
The Data
The data which we wanted to migrate were video files (transcoded/raw), and thumbnails (JPEGs). These files were stored in S3 Buckets, although organized but had a different prefix for each type of video.
Each video file had multiple encodings, resolutions, and was living in the buckets with different prefixes.
What is the size of the data if you ask, thousands of terabytes is the answer. It grows at the rate at which videos are created in Takatak (~ 1.5M/day), assuming 15MB as the average of each video file, with its transcoded part we are looking at a ~15MB * 1.5M = ~22TB of raw data dumped every day into the bucket. This data would be then encoded and stored which resulted in more data.
With each passing day, we were breaching our timelines to start live migration and eventually delaying the app release.
We had around 700Million videos to be migrated from TakaTak to MOJ Takatak within “DAYS”. All this data was mandatory to train our models for the feed, start the QA and launch the alpha version for the initial test.
The Options
gsutil is a Python application that lets you access Cloud Storage from the command line.
Pros:
- Easy to set up and use.
- Works with S3 and GCS out of the box.
- Multithreading Support.
Cons:
- Not recommended for migrating large amounts of data, as the speeds won’t be enough which will result in delay in the transfer.
- Not much configurable.
Gsutil is an amazing util, we used it multiple times to transfer files from and to the clouds. We definitely recommend gsutil if the file size is small.
Google Transfer Service [Recommended by Google Support team]
Google transfer service offers data migration between clouds. It is a managed service by Google which provides transferring data between public and private clouds. It works well out of the box.
Pros:
- Supports transfer between private and public clouds.
- Supports transfer from public urls.
Cons:
- Speeds are not up to the mark for transferring data in large volumes and where files are large in number.
We initially chose this solution as this was recommended by Google support team because of its simplicity. The solution was pretty simple to set up but couldn’t meet our requirements, as we wanted something which is more configurable, has more throughput , because the only one thing that we didn’t have was time.
Transfer Appliance is a high-capacity storage device that enables you to transfer and securely ship your data to a Google upload facility, where google uploads the data to Cloud Storage.
Pros:
- Suited for data that is in terabytes.
- Google handles the upload of the data.
- Data can be encrypted by the client and is safe in transit.
Cons:
- Not suitable for data beyond 300TB, as it would require ordering multiple appliances as max capacity supported is 300TB, which will add to more costs.
- Ordering Transfer Appliance plus data upload takes a lot of time.
We removed this solution from our list because we didn’t have much knowledge about the procedure to order the appliance and plus it had some limitations in terms of the data that can be transferred per machine.
Time taken to transfer X PB of data
Calculator to calculate how much time it takes to transfer X amount of data

Google Transfer Service
We did a POC on Google Transfer Service to see whether it can solve the problem. In our initial run, we were getting speeds up to 2 GB/s and increasing. We assumed that these will increase as we proceed. But when we ran the job for the final data the gains started diminishing, and we ended up at speeds around ~700MB/s.
We ran the job for multiple days to see if we could see speed boosts, but no gains. We spent three days, and now we were three days behind our data migration schedule.

Next Steps
After spending three days without any gain, we were in dire need to build a custom solution to tackle this problem.
We needed a fast, reliable, fault-tolerant, and horizontally scalable system. We searched all the available solutions, but each of them had some features missing that we wanted. Our video files were stored with different prefixes whose metadata was stored in one database, then some videos were not transferred as either they were not suitable for consumption or had errors in them, this stopped us from doing a bucket-to-bucket dump.
We went ahead and thought of building our custom solution using PUBSUB and GOLANG. Which turned out to be way better than our expectations. How much better? You’ll be amazed.
Our Solution
Our solution exploits the throughput prowess of PUBSUB and the concurrency of GOLANG.
Using pubsub we could add more and more machines and scale it to the extent where we were limited by the internet bandwidth or pubsub throughput.
So by using our custom code, we enriched the metadata of videos with features that helped us in ingesting the videos as soon as they were uploaded to our buckets, which was not possible with any transfer service, because that’s what transfer services do, “transfer data”.
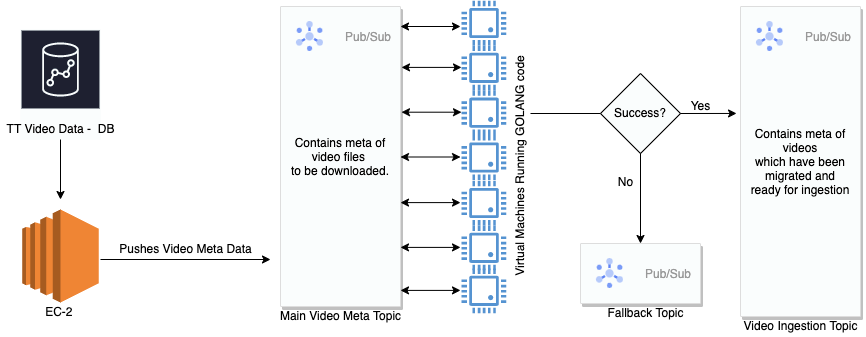
Data Migration Pipeline
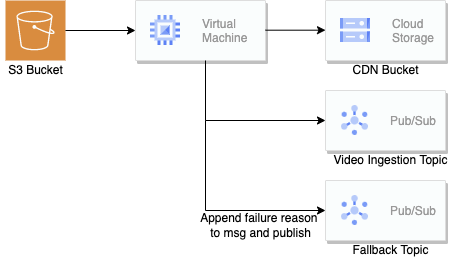
GOLANG Consumer
The Setup
We used ec2-instance to push video meta from Cassandra to our pubsub. Then we deployed our custom golang consumer on each VM to consume messages from the pubsub and perform our custom logic to find and fetch video files in S3 (this was important as we discussed we had to find the files in multiple places if they didn’t follow the standard naming process).
Procedure
1. Fetch the video file mentioned in the video meta.
2. If found, download the file, verify the ETAG of the downloaded file with ETAG fetched from S3, upload the file to CDN GCS Bucket, and verify the MD5 of the uploaded file with one calculated for the downloaded file.
3. If the file is not found, search in other locations and repeat step two.
4. In case a video file is missing or any integrity check fails, push this to the fallback topic.
Config of VMs
VM: n2-highmem-16 Machines with 128GB RAM and 1.5TB Disk Space x 20 (although we didn’t require such high disk space, unfortunately, the disk throughput only scales with more disk space in the cloud universe).
Such high memory helped us to fetch huge amounts of msgs in each call and handle a large amount of data at once.
Advantages
1. We could add more machines to speed up the transfer as our system was horizontally scalable.
2. We didn’t need to care for errors as there were integrity checks on both sides, upload, and download.
3. We could add any custom logic to the code and perform desired operations on the video file.
Why did we choose Golang?
If you would have explored languages with good concurrency and low memory footprint, you might have heard of Golang. We could have chosen any language to transfer the data, but where golang outshines others is the ease of handling concurrency and lower memory footprint of its go-routines.
Goroutines are scheduled on green threads which are managed by Golang using context-switching over actual CPU threads. Goroutines can communicate with other goroutines using channels, which makes building highly concurrent systems much easier.
Golang also eats up less memory while running so we could dedicate the memory to the actual processing. Being compiled, garbage collected, and statically typed language it helps in eliminating the errors at the compile time only and it also offers a good amount of GC tuning (if you need it).
Google’s Offering v/s Our solution (made from google’s services):
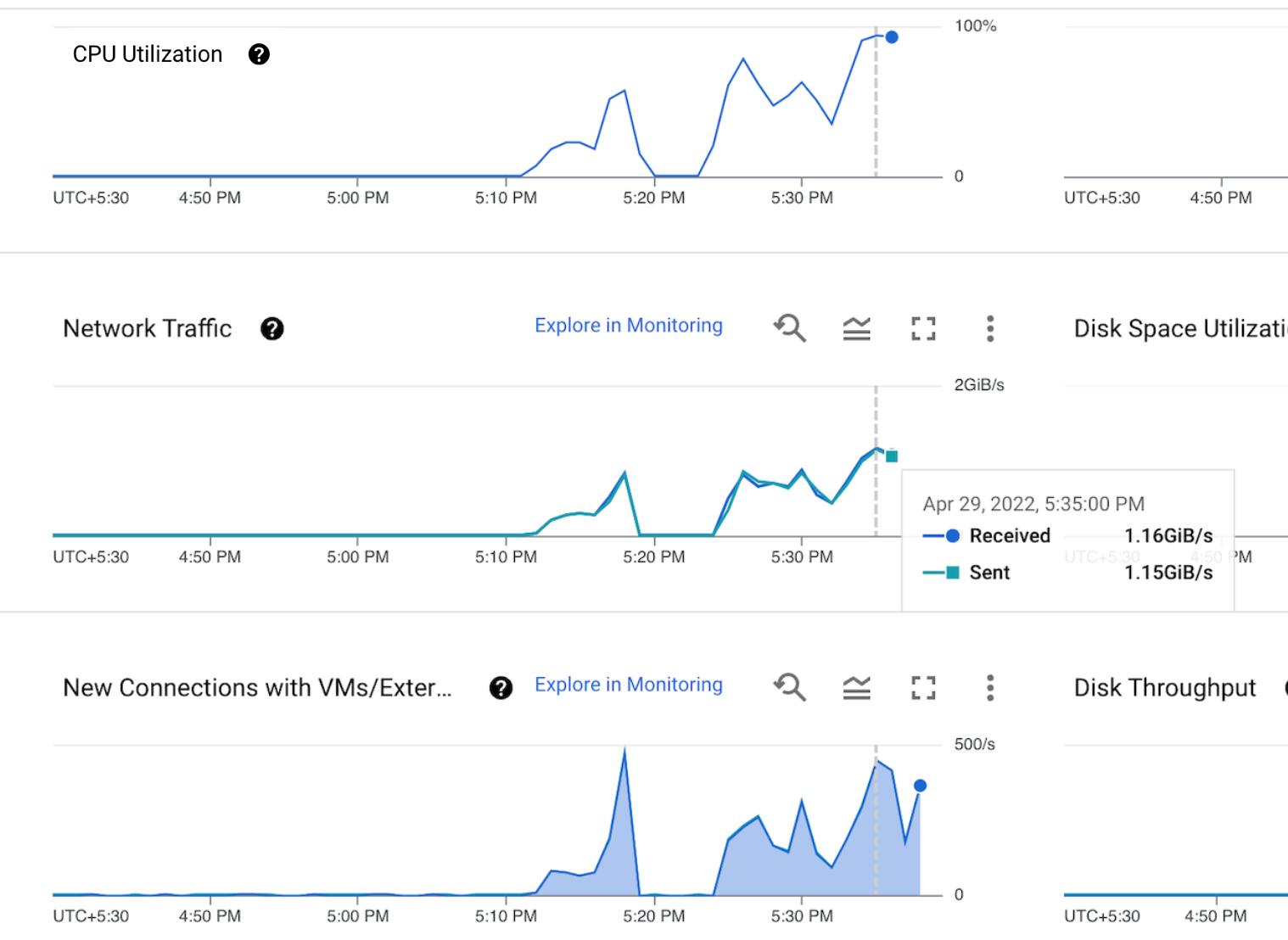
Network throughput of our solution (One golang consumer)
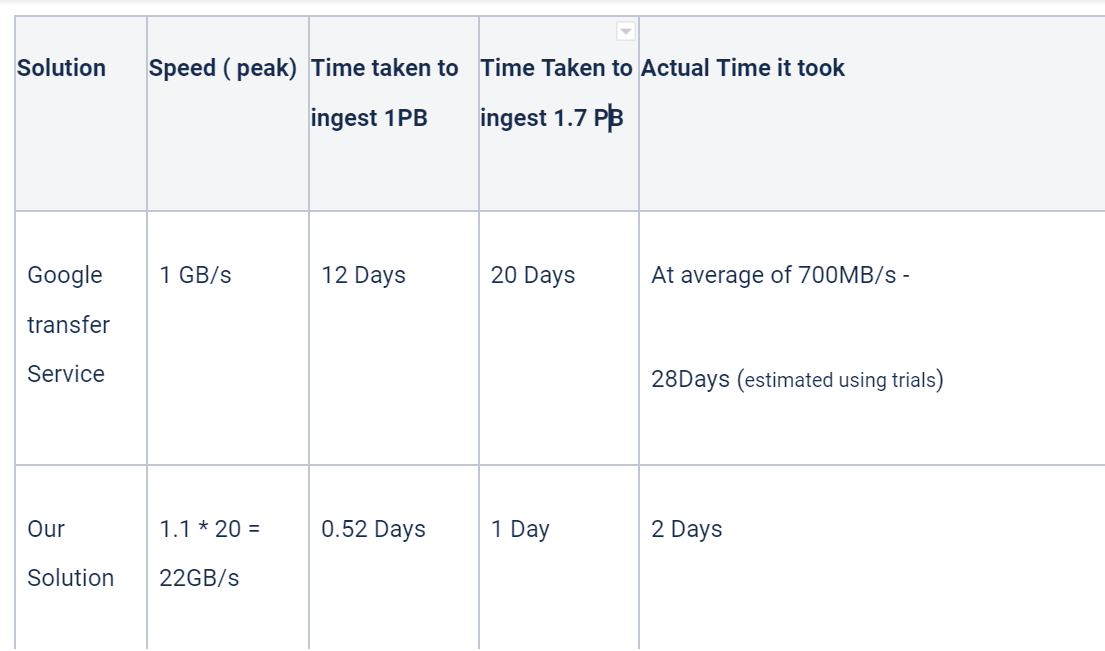
Benchmarking of the solutions
As we can see, we performed the transfer 14x faster than the Google transfer service. Considering the solution was built within days, we did a good job in creating our own transfer service that catered to our use case perfectly.
The Learnings
Sometimes cloud managed services are not what you are looking for, it’s better to combine multiple cloud offerings and build a custom solution when the requirement is not satisfied with the already available solutions.
We didn’t take much time to build the solution, we were already familiar with pubsub and golang. These timelines could vary from person to person, we were fortunate to have enough knowledge about google cloud services.
Sometimes we can exploit simple features to achieve much better results, we chose golang for this setup as concurrency is something that is already well developed in golang and very easy to use and manage.
We read each of the SDK documentation of AWS and GCP to understand the optimizations which could speed up things for us such as adjusting the chunk size of downloads and uploads, adjusting the number of go-routines, and the number of max messages, etc. This not only helped in building an efficient and fast system but also helped in speeding up the development time.
Resources:
1. Concurrency — An Introduction to Programming in Go | Go Resources
2. What is Pub/Sub? | Cloud Pub/Sub Documentation | Google Cloud
3. https://aws.amazon.com/sdk-for-go/
4. Package cloud.google.com/go/storage (v1.23.0) | Go client library | Google Cloud

