ShareChat Infrastructure: Past, Present & Future
Prakhar Joshi30 May, 2022

Written by Prakhar Joshi
ShareChat has grown by multiple folds in terms of technology and people within a short span of time. We are building new applications and improving our system on a daily basis and this leads to a fast and dynamic atmosphere within the organization. We are making a lot of new and exciting things to tackle real-world engineering problems.
This will be ShareChat’s infrastructure journey and the changes in the process over the course of time. This blog specifically focuses on the overview of the decisions we have made to improve the system and the rationale behind these decisions. We will also cover the benefits we have made with these changes and how it has helped us in improving our infrastructure management, stability, and reliability along with cost optimization
Existing Infrastructure: what and why
All ShareChat services are hosted on Google Cloud Provider (GCP). They make use of various external services like Google Pub/Sub as a message broker, Google Spanner as a relational database, Google BigTable as a non-relational database, Google Cloud Storage (GCS) as an object store, and Google CDN as CDN, RedisLabs managed Redis instance as a distributed cache. Applications are deployed on Google Kubernetes Engine (GKE).
Data layer
ShareChat applications process, generate and store around 6-8 PiB of data every day. The data can be content such as videos, images, and audio, and meta information like tags, likes, and comments. Different kinds of analytics may be performed on the data. Every operation is associated with a business logic typically triggered by the actions of an end-user.
Based on the type of data to store (like spatial, blobs, graphs), access requirements of data (consistent vs eventually consistent, reads to write ratio, query operations like join), and scale of data a database solution may be better suited than others.
- Relational databases:Google Spanner & CloudSQL
- Non-Relational databases: Google BigTable, ScyllaDB & MongoDB
- Object store databases: Google Storage Buckets (GCS)
- Search databases: Elastic Search, Milvus
- Data Warehouse: Google BigQuery, Apache DRUID
Caching layer
At ShareChat, application performance is one of the most important SLAs we focus on, and to achieve this one major metric is latency. Latency can directly affect some key business metrics. Caching of frequently accessed data is one popular method to decrease latency and also alleviate the load on backend systems.
- In-Memory Cache: Redis, Memcache
- CDNs provided by Google, Amazon, Tencent, Akamai
Message Broker
Message brokers are used for event-based communication between microservices, asynchronous processing of data, real-time analytics and monitoring, data ingestion, data integration, and data replication. At ShareChat, most applications rely on Google Pub/Sub, Kafka, and Redis-streams.
Application Layer
ShareChat applications are developed following microservice-based architecture. Services may communicate synchronously or asynchronously. Synchronous communication is a blocking call in which an upstream service needs a response from a downstream service to build its response.Whereas in asynchronous communication the upstream service does not wait for a response from the downstream services to build its response. It just sends the message to a topic in a message broker which interested services can subscribe to for further processing.
ShareChat services are written in NodeJS, Java, and GoLang. Services uses Cortex, where all information about a service like downstream services, various dashboards, and slack channels are defined.
Communication between ShareChat client and server applications as well as inter-service communication is via REST over HTTP 2.x. Other protocols like gPRC are also being explored for inter-service communication which offers better performance at cost of flexibility.
Traffic Routing
Internal tools and client applications interact with ShareChat services. An example of an Internal tool is a web tool for the operations team to take actions like blocking a suspicious user.
The entry point for ShareChat services is a Google load balancer exposed on public IP which routes traffic to an internal subdomain within ShareChat VPC based on URL mapping defined in API Gateway. The internal domain name resolution happens via Cloud DNS which maps the internal domain to the Nginx.
client -> DNS -> GCLB -> API Gateway -> Nginx ingress -> kubernetes service -> service pods
Deployments
At ShareChat we are using inhouse Jenkins and Spinnaker for CI (Continous Integration) and CD(Continuous Deployment) respectively. Jenkins <-> Spinnaker combo works seamlessly with each other. Each application has its own Jenkins and Kubernetes definitions defined for its CI & CD purpose. Each service communicates with the other via the internal Nginx layer.
Issues with the existing system
As we grow as an organization, we have realized the current Infrastructure setup won’t scale as expected and might be time-consuming as we turn more mature in terms of insights and quality.
CI
- Each application builds its own image from scratch, quite difficult to track versions for base modules.
- Build time got longer and longer as we introduced more features since there were no runtime-specific agents.
- Developers need to understand groovy scripts and plugin implementations for Jenkins files.
CD
- Each application defines its own k8s object which leads to standardization issues across applications.
- K8s-related changes across the organization require changes to all application’s manifest files.
- No centralized place to control how and what k8s objects should be deployed.
Service to service communication
As we mature, we need more observability across service-to-service communication like API level monitoring, tracing request lifecycle, retry logic, and traffic shadowing.
Looking out: better & optimized process
As an infrastructure engineer, it was a nightmare to manage these applications and monitor the application releases along with new feature rollouts across the organization. It was high time to think about building a system that can solve these problems and should be developer-friendly.
We had to make sure the system should be designed in such a way that we extract infrastructure-related concepts from the developer’s application deployment as much as possible. With these requirements in mind, we started looking out for solutions for automated and better CI/CD processes and service-to-service communications. As simple as it sounds, it was no walk in the park. The solution needs to be serving all the use cases and be easily integrated with the current system at the organization.
Scale is always a crucial factor for adopting any tool/technology at ShareChat, so we need to make sure the solution that we choose should scale to handle the growing traffic at ShareChat.
We knew this would be a critical decision, so we spent some time finalizing the solution as this will be the foundation for the system which we will be building. We have brainstormed around a lot of solutions for service mesh and the CI/CD process. Also, we love Jenkins and spinnaker so the new CI/CD process needs to be wrapped around these tools only.
- Rolled out runtime base images and also spin runtime specific agents which reduces the build time.
- Pre-defined stages for Jenkins like package, test, build, and push can be defined via YAML files.
- Application deployment via helm charts (maintained by the infrastructure team). Developers need to define an application-specific values file that is used while rendering the helm chart during the CD process.
- Linkerd for service-to-service communication to get better observability metrics and tracing across the request lifecycle.
- Better support for features like canary releases, traffic shadowing and retry logic for service-to-service communication.
Test it: the best way to be sure
Jenkins and Spinnaker have already tested out solutions but linkerd is something new that we are introducing and will be part of the request lifecycle. Because of the impact and behaviors of linkerd we need to test this feature before rolling it out at the organizational level.
We have tested out linkerd in multiple scenarios like the failure of pods, pods restart at higher load and linkerd was able to handle these scenarios quite well. Let's discuss one of the scenarios which we have tested out with linkerd. We have injected linkerd to one of the services and started generating load.
Below is the load test setup:
Average of requests generated for the load test over the time period:
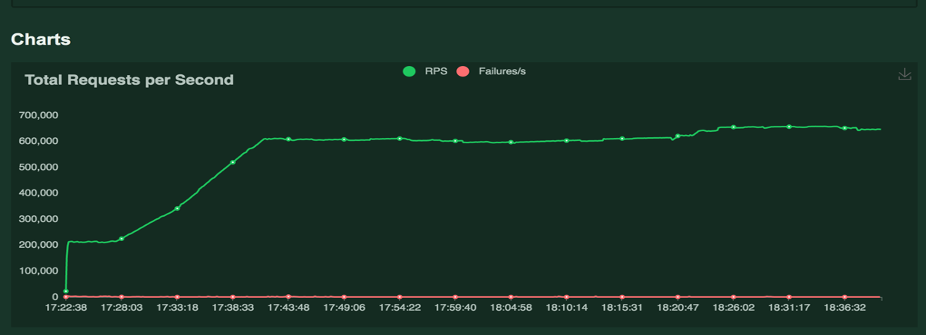
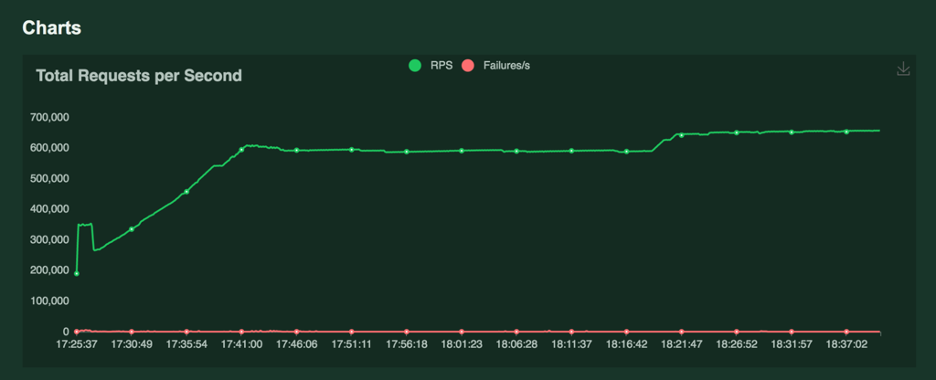


Now let's discuss how application and ingress behave with and without proxy during the load test:
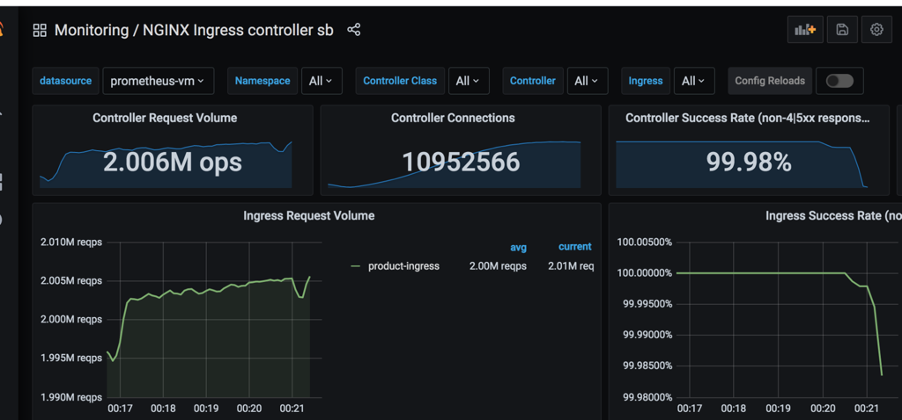
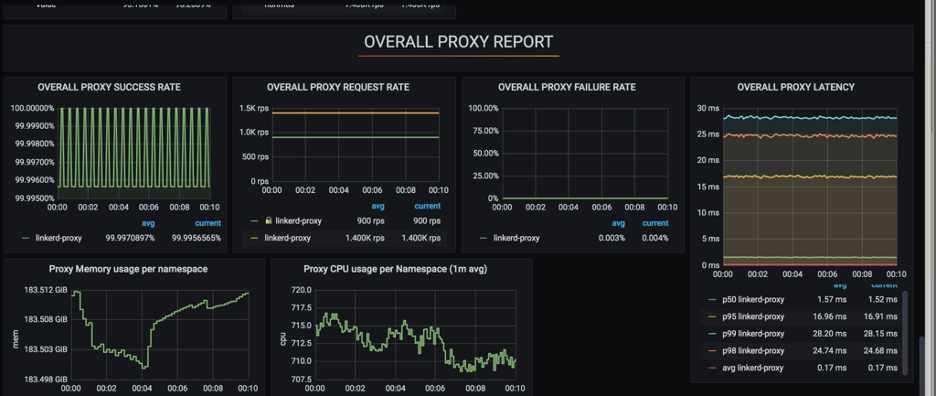
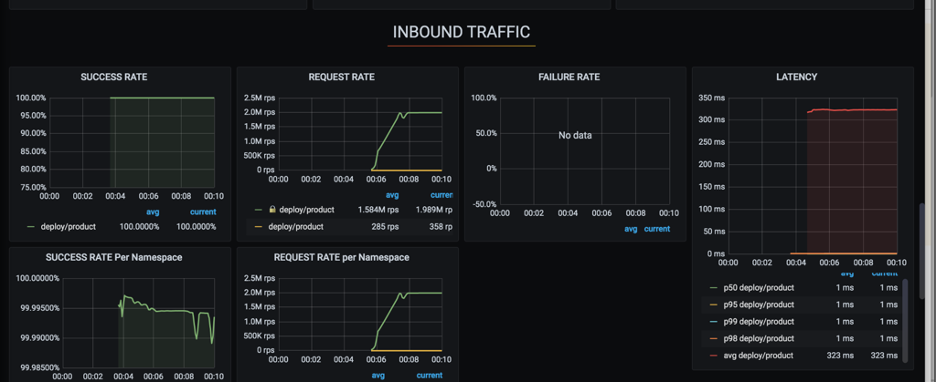
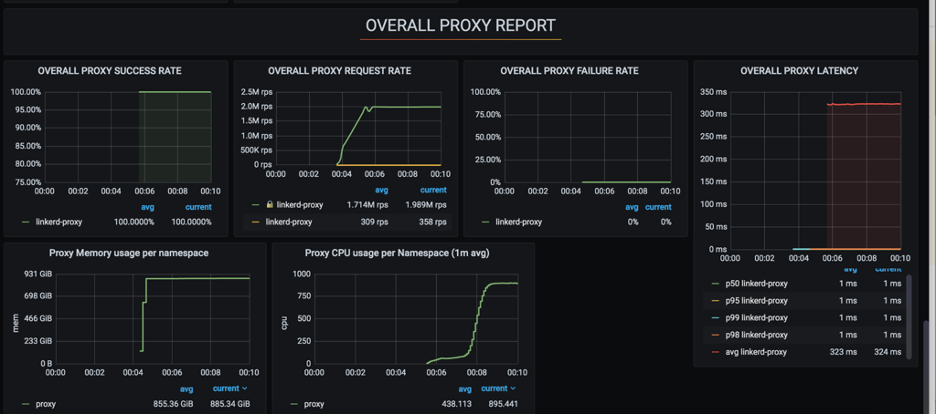
The above results were quite satisfactory for us to move ahead with linkerd.
We have performed POC for new helm deployment which helps in keeping the core infrastructure-related configurations at a central place and can be handled by the infrastructure team.
Similarly for the CI process, we performed POC to make sure developers should not worry about writing docker files, rather they should build their applications in a similar fashion as they do it in their local. Quite interesting, right?
Automation: Fast and Standard process
At ShareChat, every new tool or technology that we introduce goes through a standard process that makes sure the tool/technology is empowering developers in their day-to-day work, automated, and easy to use for the developers. The whole process is unbiased and open for everyone to participate. We follow this process to ship high-quality products across the organization.
Okay, so till this point it felt like we have bitten off more than we can chew since we had a lot of new things to say be service mesh, CI, CD, observability, and many more. We can’t even think about doing these things manually so we had to come up with some sort of automation in place which can add features like service mesh integration, detailed route level monitoring, traffic shadowing, and canary without many changes.
Also, at ShareChat we have 150+ k8s clusters so installing solutions like linkerd to k8s clusters along with their components like viz, jaeger, multicluster, etc is hectic and repetitive work. We have built automation for deploying linkerd and its components to any k8s cluster with a single click of the pipeline. This will deploy linkerd, viz, jaeger, dashboards to a specific cluster, linking clusters for multi-cluster features of linkerd. The automation will also perform checks if linkerd and its components are installed properly.
We have also integrated onboarding of linkerd and other components like canary deployment, and traffic shadowing with the helm deployment so now developers just need to enable these flags and provide custom configs if required to enable linkerd proxy for their pods, quite fascinating!!
Why? and How?
“Resistance is the first step to change”. As we were making changes, we also faced a lot of questions like why? What are the advantages of this system? Is this worth spending time on? We can now proudly say that YES, these new systems have helped us a lot in terms of management of infrastructure, reducing build time, improving observability, and reducing time to production for applications by removing a lot of infra concepts from the whole process like dealing with k8s objects, writing docker files.
CI
We have observed a reduction in application build time by half on average. This means we are running our Jenkins agents for half the time as compared to earlier which will lead to cost reduction. Now we can also control what will be built within the docker file and which packages will be used in production. We can also patch security vulnerabilities without asking developers to make changes in their respective applications since we maintain the base images.
CD
Similarly, for the CD process, developers don’t have to worry about writing k8s objects, they just need to deal with their application-specific values. Also, if there are any changes in the k8s object’s API version we can make changes in a centralized place instead of many changes in each and every application.
Communication
With service mesh in place, we have a lot of control over service-to-service communication like retry logic, traffic splits, and shadow mode. We have better observability around API level monitoring for services. Better and automated canary releases for applications. The canaries can be promoted based on service performance calculated using metrics.
Service Mesh: is it a must to have?
As good as it sounds, service mesh does have its own pitfall. Service mesh is helpful in large systems, but it might be overkill for smaller systems where there are only a few applications. The management of service mesh requires some effort like installing components and monitoring the components. It is good to have API level monitoring, but it might not be useful in every scenario as there is a trade-off between quality vs efforts. We can still survive with topline applications level metrics but as the organization matures and grows it becomes a necessity instead of good to have features.
Service mesh also increases the load on infrastructure as you have a proxy running along with every pod which might increase the cost as compute increases but if managed properly it provides features that compensate for these extra costs. For e.g.: if we keep 0.1 core of CPU for proxy then per 10 application pods it's adding 1 core of extra compute. Again, it's a trade-off we have to make.
Finally, we have benefited from these new processes which have been introduced, we have saved a lot of developers' efforts, ship time, better management for infrastructure, cost-saving in most of the cases, more insights into the request lifecycle, and better canary releases. But the most important one is the automated and standard process across organizations for releasing any feature for any application.
Cover illustration by Ritesh Waingankar

